범위 검색은 마지막에 한 번만 사용!
이러한 제약 때문에 복합 인덱스를 설계할 때는 다음과 같은 순서를 따르는 것이 매우 중요하다. 등호(=) 조건을 사용하는 컬럼을 앞에, 범위 조건을 사용하는 컬럼을 뒤에 둔다.
예를 들어 아래의 쿼리가 자주 사용된다면?
select * from items where category >= '패션' and price = 20000;- 최적의 인덱스는 순서를 변경해서 (price, category) 순서를 사용해야 한다.
- 왜냐하면 "price = 20000"이라는 등호(=) 조건을 먼저 처리해서 검색 대상을 크게 줄일 수 있기 때문이다.
(price, category) 순서의 인덱스를 추가하자
create index idx_items_price_category_temp on items(price, category);- 임시로 사용할 예정이라 temp를 붙여두었다.
explain select * from items where category >= '패션' and price = 20000;
- 옵티마이저는 "idx_items_category_price", "idx_items_price_category_temp" 두 인덱스 중에 "idx_items_price_category_temp"가 더 효율적이라고 판단한다.
- Extra(Using index condition), rows(1), filtered(100.00)을 통해 인덱스를 통해 하나의 데이터를 찾았고 해당 데이터가 별도의 필터링 없이 바로 선택된 것을 확인할 수 있다.
idx_items_price_category_temp 인덱스
- 인덱스에서 price가 "20000"인 데이터 블록을 매우 빠르게 찾는다(lookup). 이는 인덱스가 "price"로 정렬되어 있기 때문에 가능한, 가장 효율적인 "ref" 방식(=)의 접근이다.
- 그렇게 찾아낸 좁은 데이터 집합 안에서 "category >= '패션'"이라는 범위 조건을 만족하는 데이터를 찾는다.
- 여기서는 '패선', '헬스/뷰티'를 만족하면 된다.
- price가 "20000"인 데이터들은 이미 "category" 순으로 정렬되어 있으므로, 이 과정 역시 효율적인 "range"스캔으로 처리된다.
이처럼 가장 변별력 있는 등호(=) 조건을 먼저 처리해서 작업 범위를 최대한 좁히고, 그 다음에 범위 조건을 처리하는 것이 인덱스 설계의 핵심이다. 만약 순서를 반대로 (category, price)로 했다면, "category >= '패션'"이라는 범위 검색이 먼저 수행되면서인덱스의 효율이 떨어졌을 것이다. 결론적으로, 복합 인덱스를 설계할 때는 어떤 쿼리가 주로 사용될지 예측하고, 해당 쿼리의 "WHERE" 절에 맞게 "등호 조
건 컬럼 범위 조건 컬럼" 순서로 구성하는 것이 성능 최적화의 지름길이다.
기존 인덱스를 잘 활용하자
그런데 이처럼 인덱스를 계속 만드는 것 만이 능사는 아니다. 인덱스를 추가하면 그 만큼 관리 비용이 들어간다. 기본적으로 기존에 있는 인덱스를 최대한 잘 활용하고, 그래도 안되면 인덱스 추가를 고려해야 한다.
사실 이번에 생성한 "idx_items_price_category_temp" 인덱스 없이, 기존에 만든 "idx_items_category_price" 인덱스로도 최적의 성능을 활용할 수 있는 방법이 있다.
실무 팁: IN절 활용하기
범위 조건 때문에 두 번째 인덱스 컬럼을 활용하지 못하는 이 문제는, ">" 나 "<" 같은 범위 대신 "IN" 절을 사용함으로써 해결할 수 있는 경우가 많다.
MySQL 옵티마이저는 "IN (...)"을 하나의 큰 범위로 취급하지 않고, 여러 개의 동등 비교(=) 조건의 묶음으로 인식하기 때문이다. "category >= '패션', '헬스/뷰티')"와 논리적으로 동일하다. 이 쿼리를 "IN"을 사용하도록 변경하고 실행 계획을 다시 확인해보자.
explain select * from items
where category in ('패션', '헬스/뷰티') and price = 20000;
- 예상 "rows"가 "6" -> "2"로 줄어들었다. 인덱스로 찾는 범위가 더 줄어든다는 뜻이다.
- 가장 극적인 변화는 "filtered" 컬럼이 "10.00%"에서 "100.00%"로 바뀐 것이다.
- 이것은 인덱스만을 잘 활용해서 원하는 데이터를 "100%" 다 찾았다는 의미다.
- 그래서 인덱스를 통해 찾은 데이터를 "100%" 다 통과시킨다는 의미이다.
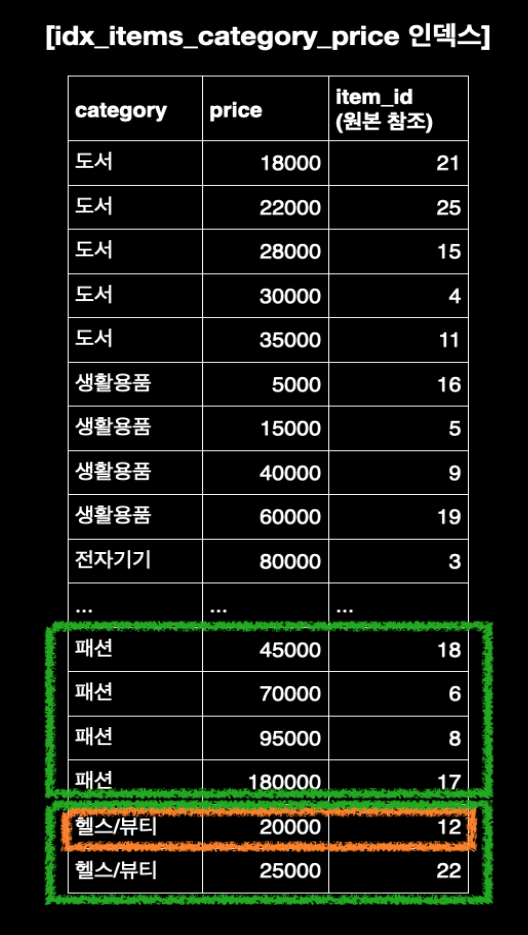
- 옵티마이저는 "WHERE category IN ('패션', '헬스/뷰티')"를 "WHERE category = '패션' OR category = '헬스/뷰티'" 와 동일하게 인식한다.
- 따라서 전체 쿼리는 내부적으로 "(category = '패션' AND price = 20000)" 또는 "(category = '헬스/뷰티' AND price = 20000)"를 만족하는 데이터를 찾는 것으로 해석된다.
- "idx_items_category_price" 인덱스를 사용해 "('패션', 20000)" 조합을 만족하는 데이터를 찾는다. (첫 번째 동등 비교)
- 이어서 "('헬스/뷰티', 20000)" 조합을 만족하는 데이터를 찾는다. (두 번째 동등 비교)
이렇게 작성한 "IN" 쿼리는 쉽게 비유하자면 다음과 같이 나누어 실행된다.
SELECT * FROM items WHERE category = '패션' AND price = 20000;
UNION ALL
SELECT * FROM items WHERE category = '헬스/뷰티' AND price = 20000;- category = '패션'만 보면 "price"가 완전히 정렬되어 있다.
- 따라서 price 컬럼도 인덱스를 사용해서 원하는 데이터를 빠르게 찾을 수 있다.
- category = '헬스/뷰티'만 보면 price가 완전히 정렬되어 있다.
- 따라서 price 컬럼도 인덱스를 사용해서 원하는 데이터를 빠르게 찾을 수 있다.
핵심은 **범위 검색이 동등 비교(=)의 여러 묶음으로 바뀌었다는 점이다. ">=" 같은 범위 조건에서는 인덱스의 두 번째 컬럼(price)을 제대로 활용할 수 없었지만, category와 price가 모두 특정 값으로 고정된 동등 비교에서는 복합 인덱스의 모든 컬럼을 효율적으로 사용할 수 있다. 즉, 옵티마이저는 "idx_items_category_price" 인덱스를 사용해 "('패션', 20000)" 지점으로 한 번, "('헬스/뷰티', 20000)" 지점으로 또 한 번, 총 두 번의 정확한 위치 탐색(seek)을 수행한다. 이 탐색 과정에서 price 조건까지 완벽하게 반영되므로, 불필요하게 데이터를 읽고 버리는 과정이 사라진다. 이것이 바로 "filtered" 컬럼이 "100.00%"로 표시되는 이유다.
결론적으로 ">"는 "연속된 범위"로 처리되어 복합 인덱스의 추가적인 활용을 막는 반면, "IN" 은 "여러 개의 개별 지점"에 대한 동등(=) 비교의 묶음으로 처리된다. 옵티마이저는 "IN" 절의 각 값에 대해 인덱스를 사용한 효율적인 탐색(Seek)을 여러 번 수행할 수 있으므로, 복합 인덱스의 모든 컬럼을 효과적으로 활용할 수 있다.
논리적으로 같은 결과를 반환하더라도, ">"는 인덱스 스캔(Scan) 방식으로 동작하여 후속 컬럼 활용에 제한이 있는 반면, "IN"은 여러 번의 탐색(Seek) 방식으로 동작하여 복합 인덱스의 모든 컬럼을 효율적으로 활용할 수 있기 때문에 성능 차이가 발생한다. 물론 "IN" 절에 들어가는 값이 수백, 수천 개로 너무 많아지면 성능이 저하될 수 있지만, 이처럼 범위 조건을 몇 개의 동등 조건으로 바꿀 수 있는 상황이라면 "IN" 절은 매우 강력한 최적화 도구가 될 수 있다.
실무에서는 범위가 한정적인 컬럼에 이 "IN" 트릭을 자주 사용한다.
예를 들어, 상품 상태를 나타내는 status 컬럼이 '판매중', '품절', '판매중지' 3가지 값만 가진다고 하자. '판매중' 또는 '품절' 상태인 상품을 찾을 때 "WHERE status >= '판매중'"과 같이 조회하는 것보다 "WHERE status IN ('판매중', '품절')"로 조회하는 것이 복합 인덱스를 활용하는 데 훨씬 유리할 수 있다.
물론, "IN" 절에 들어가는 값의 개수가 너무 많아지면 오히려 성능이 저하될 수도 있으므로, 항상 "EXPLAIN"을 통해 실제 실행 계획을 확인하고 결정하는 것이 현명하다.
'데이터 베이스 > 데이터베이스 기본' 카테고리의 다른 글
| Ch08. 데이터 무결성 - 데이터 무결성이 중요한 이유 (0) | 2026.06.07 |
|---|---|
| Ch07. 인덱스 - 복합 인덱스 정리 (0) | 2026.06.07 |
| Ch07. 인덱스 - 복합 인덱스(2) (0) | 2026.06.07 |
| Ch07. 인덱스 - 인덱스의 단점과 주의사항 (0) | 2026.06.06 |
| Ch07. 인덱스 - 인덱스 설계 가이드라인 (0) | 2026.06.06 |