"카테고리가 '전자기기'인 상품들 중에 가격이 100,000원 이상인 상품을 보여줘" 이러한 요구사항이 들어왔다.
SELECT * FROM items
WHERE category = '전자기기' AND price >= 100000- 다중 조건 쿼리의 성능을 최적화하기 위해 사용하는 것이 바로 복합 인덱스(Composite Index) 또는 다중 컬럼 인덱스(Multi-column Index)다.
- 복합 인덱스는 이름 그대로 두 개 이상의 컬럼을 묶어서 하나의 인덱스로 만드는 것이다
- 하지만 복합 인덱스를 제대로 사용하려면 한 가지 매우 중요한 규칙을 이해해야 한다. 바로 "컬럼의 순서"다
왜 컬럼 순서가 중요할까?
복합 인덱스의 동작 원리는 우리가 실생활에서 사용하는 "전화번호부"나 "국어사전"과 똑같다.
- 전화번호부: "성(Last Name)"으로 먼저 정렬된 후, 같은 성 안에서 "이름(First Name)"으로 다시 정렬된다.
- 국어사전: "첫 번째 글자"로 먼저 정렬된 후, 같은 첫 글자로 시작하는 단어들끼리 "두 번째 글자"로 다시 정렬된다.
items 테이블에 "(category, price)" 순서로 복합 인덱스를 만들었다고 상상해 보자. 이 인덱스는 내부적으로 다음과 같이 정렬된다.
- category를 기준으로 먼저 정렬한다. ('도서', '생활용품', '전자기기', '패션', '헬스/뷰티' 순서)
- 같은 category 내에서는 "price"를 기준으로 다시 정렬한다.
예시
- category로 검색: 매우 효율적이다. 인덱스의 앞부분만 보고 빠르게 찾을 수 있다. (예: "전자기기" 섹션으로 바로 점프)
- category와 price로 검색: 역시 매우 효율적이다. "전자기기" 섹션을 찾은 뒤, 그 안에서 "price" 순으로 정렬된 데이터를 탐색하면 된다.
- "전자기기" 안에서는 "price"가 항상 정렬된 상태를 유지한다.
- 각각의 카테고리 안에서는 "price"가 항상 정렬된 상태를 유지한다.
- "1차 정렬"의 기준 안에서 "2차 정렬"은 항상 정렬된 상태를 유지한다.
- price만으로 검색: 매우 비효율적이다. 전화번호부에서 성은 모르고 이름 만으로 찾는 것과 같다.
- price 값은 각 "category" 섹션마다 흩어져 있기 때문에, 인덱스 전체를 다 훑어봐야 한다.
- 이런 경우 옵티마이저는 차라리 풀 테이블 스캔을 선택할 수도 있다.
"idx_items_category_price" 인덱스 예시에서 price 컬럼만 딱 분류해서 보자. 가격순으로 정렬이 되어 있는 것같아 보이지만 중간에 정렬이 다시 틀어진다. 결과적으로 "price" 컬럼만 보면 정렬이 되어 있지 않다. 결과적으로 1차 정렬의 기준 없이 2차 정렬의 값만 가지고는 정렬된 상태를 유지할 수 없다.
이처럼 복합 인덱스는 첫 번째 컬럼을 기준으로 정렬된 상태에서만 제 역할을 할 수 있다. 이를 인덱스 왼쪽 접두어 규칙(Index Left-Prefix Rule)이라고 한다. 인덱스를 "(A, B, C)" 순서로 생성했다면, "WHERE" 조건에 다음과 같이 사용될 때 효율적이다.
- (A)
- (A, B)
- (A, B, C)
하지만 "(B), (C), (B, C)"와 와 같이 첫 번째 기준인 "A"가 빠진 조건으로는 인덱스를 제대로 활용할 수 없다.
복합 인덱스 대원칙
- 인덱스는 순서대로 사용하라!(왼쪽 접두어 규칙)
- 등호(=) 조건은 앞으로, 범위 조건(<, >)은 뒤로!
- 정렬(ORDER BY)도 인덱스 순서를 따르라!
Index 생성하기
create index idx_items_category_price on items(category, price);
show index from items;
- "idx_items_category_price"는 하나의 복합 인덱스이다.
- "Seq_in_index"는 복합 인덱스의 컬럼 순서를 나타낸다.
- "idx_items_category_price"의 경우 1번은 "category" , 2번은 "price" 순서로 만들어진 것을 확인할 수 있다.
복합 인덱스 성공 예제1: category 사용
explain select * from items where category = '전자기기';

- type(ref): category가 '전자기기'인 조건을 만족하는 데이터를 찾기 위해 동등 비교(= )나 "JOIN"을 사용하고, 인덱스를 효율적으로 사용했음을 의미한다.
- 쉽게 이야기해서 Key 값 하나를 딱 집어서 찾은 것이다.
- key(idx_items_category_price): 우리가 만든 복합 인덱스가 사용되었다.
- rows(10): 옵티마이저는 '전자기기' 카테고리에 해당하는 상품이 약 10건 있을 것으로 정확히 예측하고, 그 부분만 탐색한다.
이는 (category, price)로 정렬된 인덱스에서 category가 '전자기기'인 첫 번째 위치를 빠르게 찾아낸 뒤, '전자기기'가 끝날 때까지 인덱스를 순차적으로 읽기만 하면 되므로 매우 효율적이다. 전화번호부에서 "김"씨를 찾는 것과 같이, "ㄱ" 섹션으로 바로 이동해서 "김"씨가 끝날 때까지 읽는 것과 같다.
복합 인덱스 성공 예제 2: category, price 사용
"카테고리가 '전자기기'이면서, 가격이 정확히 120,000원인 상품을 찾아보자."
explain select * from items where category = '전자기기' and price = 120000;
- type(ref): 두 개의 컬럼 조건(category, price)을 모두 만족하는 데이터를 찾기 위해 인덱스를 사용했다
- rows(1): 탐색할 행의 수가 단 "1개"로 예측된다.
데이터베이스는 먼저 category가 '전자기기'인 섹션을 찾고, 그 안에서 price가 '120000'인 지점을 탐색한다. '전자기기' 섹션 내부는 이미 "price" 순으로 정렬되어 있으므로, 원하는 데이터를 매우 빠르게 특정할 수 있다.
복합 인덱스 성공 예제 3: 복합 인덱스와 정렬
복합 인덱스의 진정한 힘은 정렬(ORDER BY) 작업을 피할 때 드러난다. "WHERE" 절의 필터링과 "ORDER BY"의 정렬 방향이 인덱스 순서와 일치하면, 데이터베이스는 불필요한 filesort 작업을 생략해서 성능을 크게 향상 시킬 수 있다.
"카테고리가 '전자기기'이면서 100,000원 초과인 상품을 가격 오름차순으로 정렬해서 보여줘." 요구 사항을 생각해 보자
explain select * from items where category = '전자기기' and price > 100000
order by price;
- Extra 컬럼에 "Using filesort"가 없다.
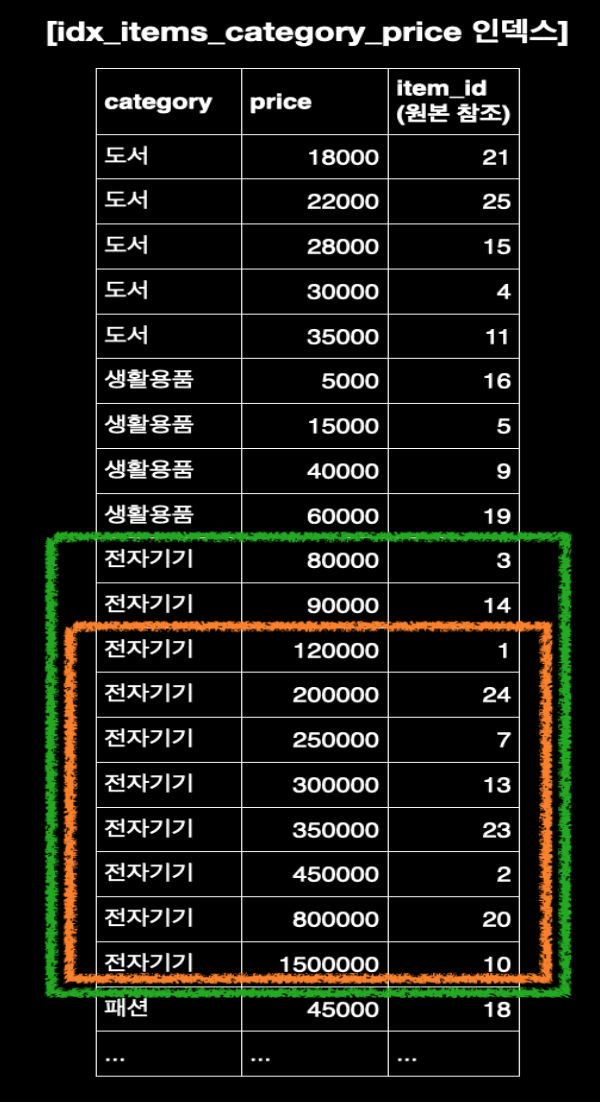
- "idx_items_category_price" 인덱스를 사용해 category가 '전자기기'인 섹션으로 빠르게 이동한다.
- 해당 섹션 내에서, price가 "100000"을 초과하는 첫 번째 데이터를 찾는다.
- 그 지점부터 '전자기기' 섹션이 끝날 때까지 인덱스를 순서대로 읽기만 하면 된다
인덱스의 '전자기기' 섹션은 이미 price 순서로 완벽하게 정렬되어 있다. 따라서 데이터베이스는 별도로 데이터를 모아 다시 정렬할 필요 없이, 인덱스를 읽는 즉시 "ORDER BY price" 조건을 만족하는 결과를 얻게 된다. 이처럼 "WHERE" 절의 조건과 "ORDER BY" 절의 조건이 복합 인덱스의 순서(category → price)와 일치하면, 데이터베이스는 가장 효율적인 방식으로 데이터를 찾고 정렬까지 한 번에 처리한다. "filesort"를 피하는 것이야말로 복합 인덱스를 사용하는 핵심적인 이유 중 하나다.
explain select * from items where category = '전자기기' and price > 100000
order by category, price;
- "ORDER BY"를 사용할 때 복합 인덱스의 순서대로 정렬하면 추가적인 정렬(filesort)을 피할 수 있다
- 여기서 복합 인덱스가 "category, price" 순서이므로 "ORDER BY"도 순서에 맞추어 사용하면 정렬을 최적화할 수 있다.
- 여기서 선택된 "category"는 '전자기기' 단 하나이므로 이런 경우에는 "category"를 정렬 조건에 넣을 필요가 없다.
- 정렬은 최소 2개 이상 있을 때 의미가 있다.
- 이런 경우에는 "ORDER BY"에 category를 두는 것이 의미가 없으므로 생략이 가능하다.
다른 필드로 정렬
explain select * from items where category = '전자기기' and price > 100000
order by item_name;
- 만약 "ORDER BY item_name"처럼 인덱스 순서와 다른 컬럼으로 정렬을 요청했다면, 조회한 결과를 다시 정렬해야 하기 때문에 Extra 컬럼에 "Using filesort"가 발생할 것이다.
'데이터 베이스 > 데이터베이스 기본' 카테고리의 다른 글
| Ch07. 인덱스 - 인덱스의 단점과 주의사항 (0) | 2026.06.06 |
|---|---|
| Ch07. 인덱스 - 인덱스 설계 가이드라인 (0) | 2026.06.06 |
| Ch07. 인덱스 - 커버링 인덱스 (0) | 2026.06.06 |
| Ch07. 인덱스 - 옵티마이저와 인덱스 선택 (0) | 2026.06.06 |
| Ch07. 인덱스 - 인덱스와 정렬 (0) | 2026.06.06 |