items 테이블의 "price" 컬럼을 사용하여 범위 검색(BETWEEN)에 인덱스가 어떻게 사용되는지 EXPLAIN으로 확인해 보자.
explain select * from items where price between 50000 and 100000;
- type(ALL): 풀 테이블 스캔이 발생했다.
- 데이터베이스는 "price"가 50000에서 100000 사이인 상품을 찾기 위해 items 테이블의 모든 상품 데이터를 처음부터 끝까지 하나씩 확인해야만 한다.
- key(NULL): price 컬럼을 조건으로 사용했지만, 이 컬럼에는 인덱스가 없으므로 사용된 인덱스가 없다는 의미의 "NULL"이 표시된다.
- rows(25): 테이블의 전체 행 수인 "25"가 표시된다. 풀 테이블 스캔을 하므로 당연한 결과다. (예측치 이므로 달라질 수 있다.)
- filtered(11.11): 스캔한 25개의 행 중에서 "WHERE price BETWEEN 50000 AND 100000" 조건을 만족하는 행은 약 11.11% 일 것이라고 옵티마이저가 예측하고 있다. (예측치 이므로 달라질 수 있다.)
- Extra(Using where): 데이터를 가져온 후에 "WHERE"절의 조건을 사용해 필터링 작업을 수행했다는 의미다.
- 만약 인덱스를 효율적으로 사용했다면, 처음부터 조건에 맞는 데이터만 골라서 가져왔을 것이다.
- 하지만 인덱스가 없으니 일단 모든 데이터를 다 가져와서, 그 후에 조건에 맞는지 일일이 비교하는 비효율적인 방식으로 일하고 있음을 보여준다.
이처럼 범위 검색 역시 조건절에 사용되는 컬럼에 인덱스가 없다면 풀 테이블 스캔을 피할 수 없다.
select * from items where price between 50000 and 100000;
- 쿼리 실행 결과를 보면 "item_id" 순서로 정렬된 것을 확인할 수 있다.
- 테이블은 "item_id" 순서(테이블에 데이터가 물리적으로 저장된 순서)대로 정렬되어 있기 때문에 풀 테이블 스캔 과정에서 WHERE 조건을 만족한 순서대로 결과가 나온다.
- 하지만 이 순서를 데이터베이스가 보장하는 것은 아니다. 그냥 내부 실행 과정에 따라서 이 순서가 되었을 뿐이다.
- 만약 "item_id" 조건으로 정렬해야 한다면 "ORDER BY item_id"를 추가하는 것을 권장한다.
Price 인덱스가 있을 때
create index idx_items_price on items(price);explain select * from items where price between 50000 and 100000;
- type(range): 가장 눈에 띄는 변화는 type이 "ALL"에서 "range"로 바뀐 점이다.
- 이는 데이터베이스가 인덱스를 사용해 특정 범위의 데이터를 스캔했음을 의미한다.
- 즉, "idx_items_price" 인덱스에서 price가 "50000" 이상인 지점을 찾은 뒤, "100000"을 초과하는 지점이 나올 때까지만 순차적으로 인덱스를 읽었다는 뜻이다.
- 테이블 전체를 훑는 풀 테이블 스캔(ALL)과 비교할 수 없이 효율적인 방식이다.
- key(idx_items_price): 쿼리 실행에 "idx_items_price" 인덱스가 사용되었음을 명확히 보여준다.
- 옵티마이저는 price 컬럼에 대한 범위 검색에 이 인덱스를 사용하는 것이 가장 효율적이라고 판단한 것이다.
- rows(5): 옵티마이저가 스캔할 것으로 예측하는 행의 수가 "5"로 크게 줄었다.
- 인덱스가 없을 때는 테이블 전체인 "25"개 행을 모두 스캔해야 했지만, 이제는 인덱스를 통해 조건에 맞는 "5"개의 데이터만 읽으면 된다는 것을 알고 있다. (예측치이다. 다를 수 있다.)
- filtered(100.00) : 인덱스를 통해서 스캔한 "5"개의 행을 "100%" 선택한다는 뜻이다.
- Extra(Using index condition): 이 부분도 중요한 최적화 정보다.
- 인덱스 정보만으로 "WHERE" 조건절을 최대한 필터링한 후, 조건을 만족하는 데이터의 전체 행만 가져왔다는 뜻이다.
인덱스 범위 검색 분석
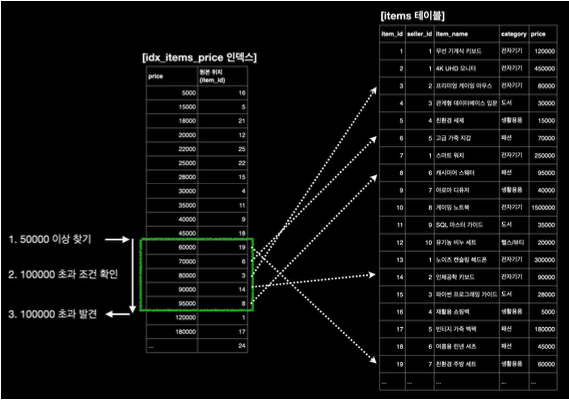
- 먼저 인덱스의 price 항목에서 "50000원" 이상인 조건을 찾는다.
- 이 조건은 이진 탐색의 원리를 사용하므로 매우 빨리 찾을 수 있다.
- 여기서는 "60000원"을 찾는다.
- price가 순서대로 정렬되어 있기 때문에 인덱스의 바로 다음 행으로 넘어가서 "100000원"을 초과했는지 확인한다. 그리고 인덱스의 다음 행으로 넘어가면서 이 과정을 반복한다.
- 다음 행은 "70000원"이다. 조건에 부합하므로 결과의 "대상"이 된다.
- 다음 행은 "80000원"이다. 조건에 부합하므로 결과의 "대상"이 된다.
- 다음 행은 "90000원"이다. 조건에 부합하므로 결과의 "대상"이 된다.
- 다음 행은 "95000원"이다. 조건에 부합하므로 결과의 "대상"이 된다.
- 다음 행은 120,000원이다. 조건에 "부합하지 않는다".
- "100000원" 초과 항목을 발견했으므로 탐색을 "종료"한다.
만약 이 인덱스가 없다면, 데이터베이스는 items 테이블 전체를 스캔하여 조건에 맞는 행을 찾아야 할 것이다. 인덱스가 범위 검색에서도 쿼리 성능을 크게 향상시킬 수 있다는 것을 알 수 있다.
select * from items where price between 50000 and 100000;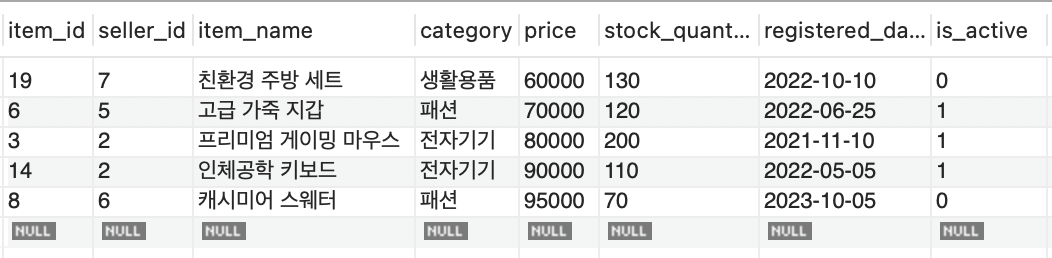
- 결과가 "price" 순서로 정렬되었다
- 인덱스가 없을 때는 "item_id" 순서(테이블에 데이터가 물리적으로 저장된 순서)로 결과가 나왔지만, "idx_items_price" 인덱스를 사용한 후에는 인덱스 키인 price를 기준으로 정렬된 결과가 나왔다.
- 이는 데이터베이스가 "idx_items_price" 인덱스를 price 순서대로 스캔하면서 조건에 맞는 item_id를 찾고, 그 "item_id"를 사용해 원본 테이블에서 데이터를 가져왔기 때문이다.
이처럼 인덱스를 사용하면 쿼리 결과의 정렬 순서가 달라질 수 있다는 점을 알아두는 것이 중요하다. 하지만 이 순서를 데이터베이스가 항상 보장하는 것은 아니다. 그냥 내부 과정의 결과에 따라서 이 순서가 되었을 뿐이다. 만약 "price" 조건으로 정렬해야 한다면 "ORDER BY price"를 추가하는 것을 권장한다.
'데이터 베이스 > 데이터베이스 기본' 카테고리의 다른 글
| Ch07. 인덱스 - 인덱스와 정렬 (0) | 2026.06.06 |
|---|---|
| Ch07. 인덱스 - 인덱스와 LIKE 범위 검색 (0) | 2026.06.06 |
| Ch07. 인덱스 - 인덱스와 동등 비교 (0) | 2026.06.05 |
| Ch07. 인덱스 - 인덱스 생성, 조회, 삭제 (0) | 2026.06.05 |
| Ch07. 인덱스 - 트리 자료 구조 (0) | 2026.06.04 |