728x90
데이터를 조회하다 보면, 우리가 원하지 않는 중복된 값들이 계속 나타나는 경우가 있다. 이럴 때 어떻게 유일한 값들만 깔끔하게 추려낼 수 있을까?
Distinct
DISTINCT는 SELECT문에서 컬럼 이름 바로 앞에 붙여 사용하며, 조회된 결과에서 중복된 행을 모두 제거하고 유일 한(unique) 값 남겨준다.
select distinct customer_id
from orders;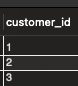
- 각 고객 ID가 한번씩만 나타난다.
- 1 , 2 , 3 번 고객이 우리 쇼핑몰에서 주문을 했다는 사실을 명확하게 알 수 있다
여러 컬럼에 DISTINCT 적용하기
DISTINCT는 하나의 컬럼에만 사용할 수 있는 것이 아니다. 여러 개의 컬럼을 대상으로도 사용할 수 있다. 이 경우, 지정된 모든 컬럼의 조합이 유일한 것들만 보여준다.
예를 들어 "어떤 고객이 어떤 상품을 구매했는지 그 조합을 중복 없이 보고 싶다"는 새로운 요청이 왔다고 가정
select customer_id, product_id
from orders
order by customer_id, product_id;
- (2, 2)라는 조합이 2번 나타난다.
Distinct로 제거
select distinct customer_id, product_id
from orders
order by customer_id, product_id;
- 결과를 보면, 중복이었던 (2, 2) 행이 하나로 합쳐져 총 4개의 유일한 '고객-상품' 조합만 남은 것을 확인할 수 있다.
실무 팁
실무에서 DISTINCT는 데이터를 탐색하고 분석할 때 많이 사용된다. "우리 서비스에는 어떤 종류의 고객들이 있지?", "판매된 상품의 카테고리는 총 몇 가지지?"와 같이 데이터의 '종류'를 파악할 때 아주 유용하다.
다만 한 가지 기억해야 할 점이 있다. `DISTINCT` 는 결과를 보여주기 전에 내부적으로 중복을 제거하기 위한 과정을 거쳐야 한다. 따라서 데이터가 아주 많은 경우 일반적인 `SELECT` 보다 성능이 저하될 수 있다. 대량의 데이터라면 성능을 확인할 필요가 있다. 물론, 대부분의 경우에는 크게 문제 되지 않으니 걱정 말고 사용해도 괜찮다.
728x90
'데이터 베이스 > SQL 첫걸음(인프런 강의)' 카테고리의 다른 글
| Ch04. 조회와 정렬 - null (0) | 2025.10.17 |
|---|---|
| Ch04. 조회와 정렬 - Limit (0) | 2025.10.17 |
| Ch04. 조회와 정렬 - order by (0) | 2025.10.17 |
| Ch04. 조회와 정렬 - where (0) | 2025.10.17 |
| Ch04. 조회와 정렬 - Select(조회) (0) | 2025.10.13 |