실행 코드
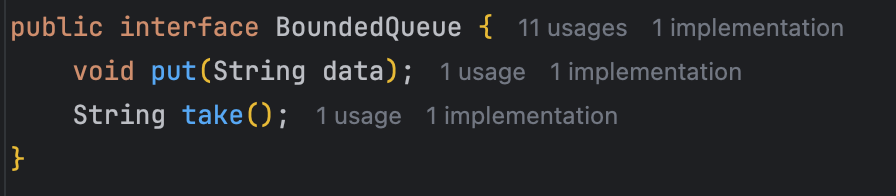
- BoundedQueue: 버퍼 역할을 하는 큐의 인터페이스이다.
- put(data): 버퍼에 데이터를 보관한다. (생산자 스레드가 호출하고, 데이터를 생산한다.)
- take(): 버퍼에 보관된 값을 가져간다. (소비자 스레드가 호출하고, 데이터를 소비한다.)
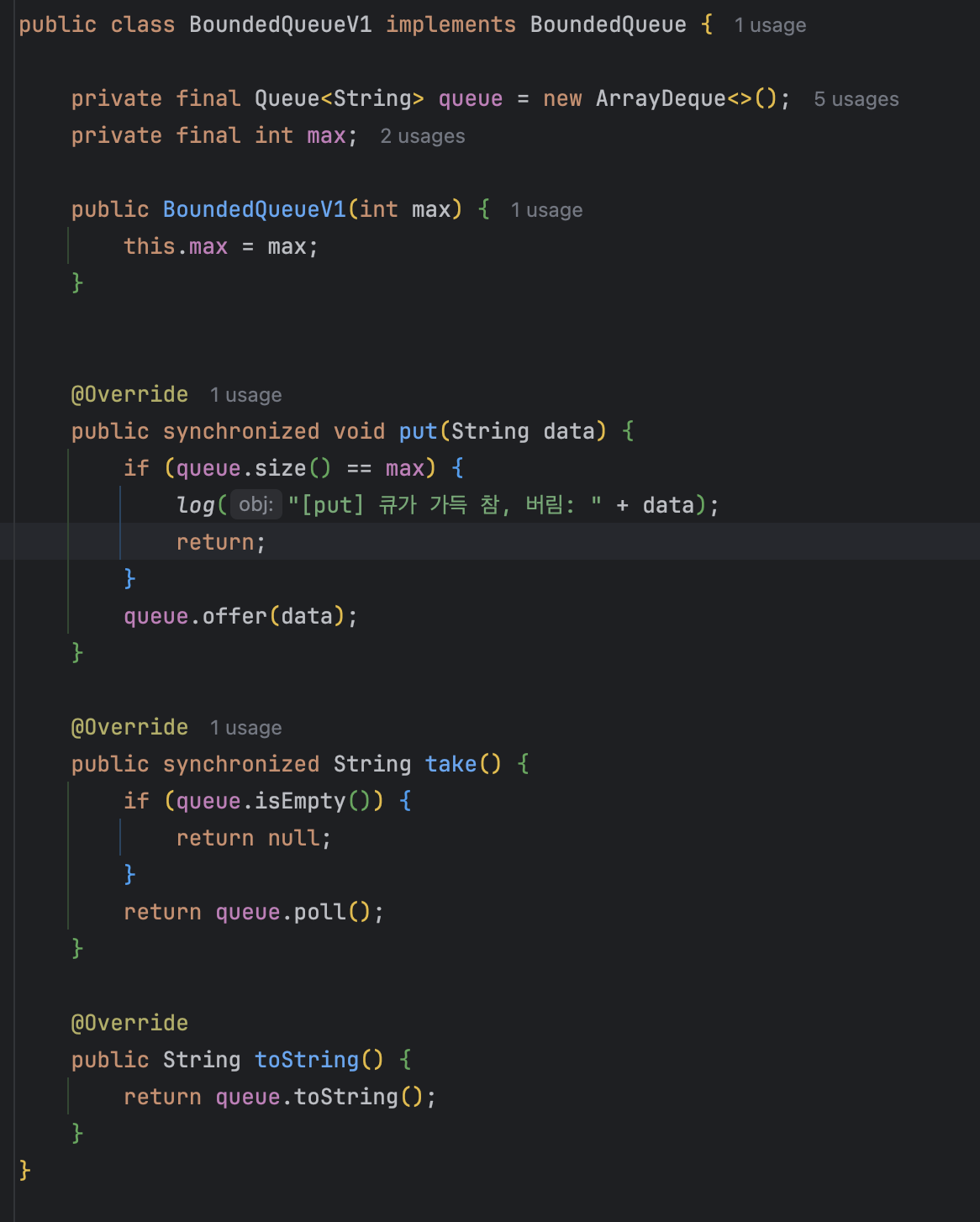
- BoundedQueueV1 : 한정된 버퍼 역할을 하는 가장 단순한 구현체이다. 이후에 버전이 점점 올라가면서 코드를 개선한다.
- Queue , ArrayDeque : 데이터를 중간에 보관하는 버퍼로 큐( Queue )를 사용한다. 구현체로는 ArrayDeque를 사용한다.
- int max : 한정된(Bounded) 버퍼이므로, 버퍼에 저장할 수 있는 최대 크기를 지정한다.
- put() : 큐에 데이터를 저장한다. 큐가 가득 찬 경우 더는 데이터를 보관할 수 없으므로 데이터를 버린다.
- take() : 큐의 데이터를 가져간다. 큐에 데이터가 없는 경우 null을 반환한다.
- toString() : 버퍼 역할을 하는 queue 정보를 출력한다.
주의!: 원칙적으로 toString() 에도 synchronized를 적용해야 한다. 그래야 toString()을 통한 조회 시점에 도 정확한 데이터를 조회할 수 있다. 하지만 이 부분이 이번 설명의 핵심이 아니고, 또 예제 코드를 단순하게 유지하기 위해 여기서는 toString()에 synchronized를 사용하지 않겠다.
임계 영역: 여기서 핵심 공유 자원은 바로 queue(ArrayDeque)이다. 여러 스레드가 접근할 예정이므로 synchronized를 사용해서 한 번에 하나의 스레드만 put() 또는 take()를 실행할 수 있도록 안전한 임계 영역을 만든다. 예) put(data)을 호출할 때 queue.size()가 max 가 아니어서, queue.offer()를 호출하려고 한다. 그런데 호출하기 직전에 다른 스레드에서 queue에 데이터를 저장해서 queue.size()가 max로 변할 수 있다!

- ProducerTask : 데이터를 생성하는 생성자 스레드가 실행하는 클래스, Runnable을 구현한다.
- 스레드를 실행하면, queue.put(request)을 호출해서 전달된 데이터( request )를 큐에 보관한다.
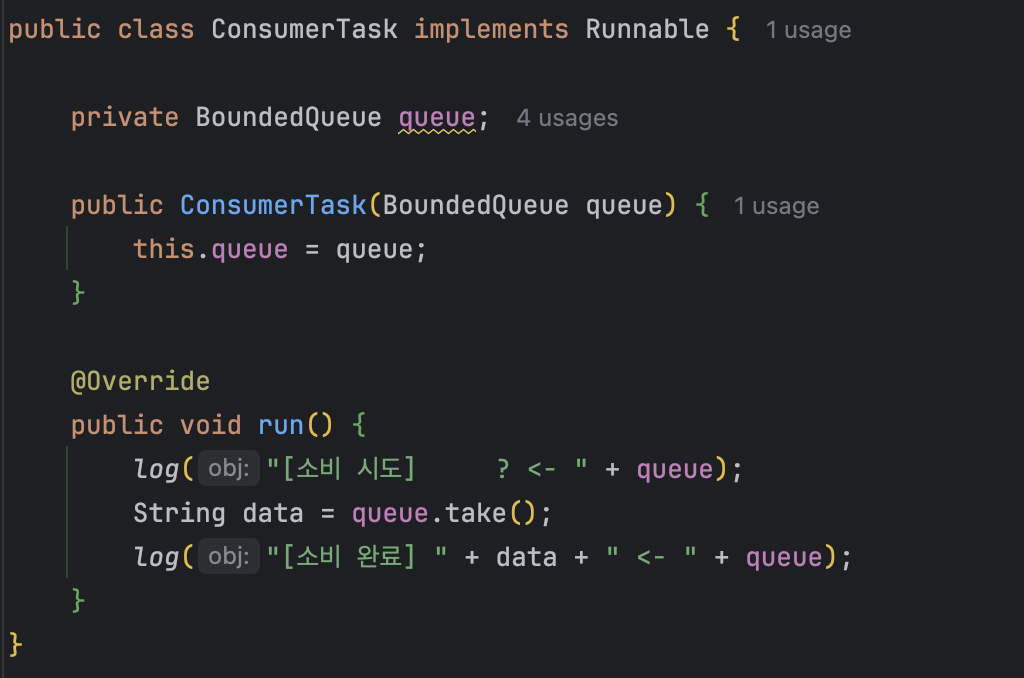
- ConsumerTask : 데이터를 소비하는 소비자 스레드가 실행하는 클래스, Runnable을 구현한다.
- 스레드를 실행하면, queue.take()를 호출해서 큐의 데이터를 가져와서 소비한다.
import java.util.ArrayList;
import java.util.List;
import static util.MyLogger.log;
import static util.ThreadUtils.sleep;
public class BoundedMain {
public static void main(String[] args) {
// 1. BoundedQueue 선택
BoundedQueue queue = new BoundedQueueV1(2);
// 2. 생산자, 소비자 실행 순서 선택, 반드시 하나만 선택!
producerFirst(queue); // 생산자 먼저 실행
//consumerFirst(queue); // 소비자 먼저 실행
}
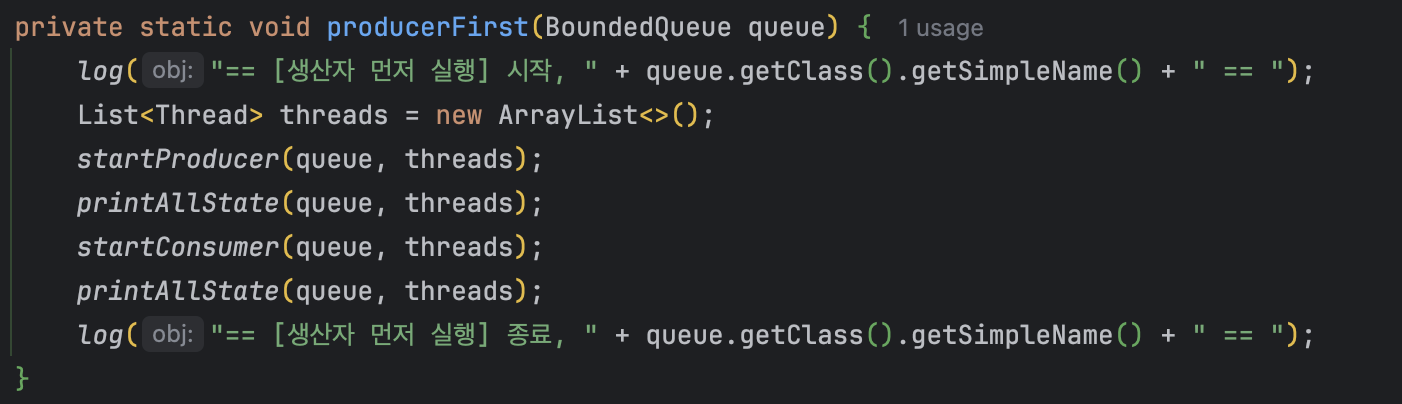
private static void producerFirst(BoundedQueue queue) {
log("== [생산자 먼저 실행] 시작, " + queue.getClass().getSimpleName() + " == ");
List<Thread> threads = new ArrayList<>();
startProducer(queue, threads);
printAllState(queue, threads);
startConsumer(queue, threads);
printAllState(queue, threads);
log("== [생산자 먼저 실행] 종료, " + queue.getClass().getSimpleName() + " == ");
}
private static void consumerFirst(BoundedQueue queue) {
log("== [소비자 먼저 실행] 시작, " + queue.getClass().getSimpleName() + " == ");
List<Thread> threads = new ArrayList<>();
startConsumer(queue, threads);
printAllState(queue, threads);
startProducer(queue, threads);
printAllState(queue, threads);
log("== [소비자 먼저 실행] 종료, " + queue.getClass().getSimpleName() + " == ");
}
private static void startProducer(BoundedQueue queue, List<Thread> threads) {
System.out.println();
log("생산자 시작");
for (int i = 1; i <= 3; i++) {
Thread producer = new Thread(new ProducerTask(queue, "data" + i), "producer" + i);
threads.add(producer);
producer.start();
sleep(100);
}
}
private static void startConsumer(BoundedQueue queue, List<Thread> threads) {
System.out.println();
log("소비자 시작");
for (int i = 1; i <= 3; i++) {
Thread consumer = new Thread(new ConsumerTask(queue), "consumer" + i);
threads.add(consumer);
consumer.start();
sleep(100);
}
}
private static void printAllState(BoundedQueue queue, List<Thread> threads) {
System.out.println();
log("현재 상태 출력, 큐 데이터: " + queue);
for (Thread thread : threads) {
log(thread.getName() + ": " + thread.getState());
}
}
}- BoundedQueue 선택(BoundedQueue queue = new BoundedQueueV1(2);)
- BoundedQueue의 구현체를 선택해서 생성한다. 이후에 점점 버전업 된 BoundedQueue의 구현체로 변경할 예정이다.
- 버퍼의 크기는 2를 사용한다. 따라서 버퍼에는 데이터를 2개까지만 보관할 수 있다.
- 만약 생산자가 2개를 넘어서는 데이터를 추가로 저장하려고 하면 문제가 발생한다.
- 반대로 버퍼에 데이터가 없는데, 소비자가 데이터를 가져갈 때도 문제가 발생한다.
- 생산자, 소비자 실행 순서 선택, 반드시 하나만 선택!(producerFirst(queue); //생산자 먼저 실행, consumerFirst(queue); // 소비자 먼저 실행)
- 이 두 코드 중에 하나만 선택해서 실행해야 한다. 그렇지 않으면, 예상치 못한 오류가 발생할 수 있다.
- 생산자가 먼저 실행되는 경우, 소비자가 먼저 실행되는 경우를 나누어서 다양한 예시를 보여주기 위해 이렇게 만들었다.
주의!: 반드시 생산자, 소비자 실행 순서 선택에서 두 코드 중에 하나만 선택해서 실행해야 한다. 생산자 먼저 실행을 선택하면 소비자 먼저 실행 부분은 주석으로 처리해야 한다!


- threads : 스레드의 결과 상태를 한꺼번에 출력하기 위해 생성한 스레드를 보관해 둠
- startProducer : 생산자 스레드를 3개 만들어서 실행한다. 참고로 이해를 돕기 위해 0.1초의 간격으로 sleep을 주면서 순차적으로 실행한다. 이렇게 하면 producer1 -> producer2 -> producer3 순서로 실행되는 것을 확인할 수 있다.
- printAllState : 모든 스레드의 상태를 출력한다. 처음에는 producer 스레드들만 만들어졌으므로 해당 스레드들만 출력한다.
- startConsumer : 소비자 스레드를 3개 만들어서 실행한다. 참고로 이해를 돕기 위해 0.1초의 간격으로 sleep을 주면서 순차적으로 실행한다. 이렇게 하면 consumer1 -> consumer2 -> consumer3 순서로 실행되는 것을 확인할 수 있다.
- printAllState : 모든 스레드의 상태를 출력한다. 이때는 생산자, 소비자 스레드 모두 출력한다.
여기서 핵심은 스레드를 0.1초 단위로 쉬면서 순서대로 실행한다는 점이다.
- 생산자 먼저인 producerFirst를 호출하면 producer1 -> producer2 -> producer3 -> consumer1 -> consumer2 -> consumer3 순서로 실행된다.
- 소비자 먼저인 consumerFirst를 호출하면 consumer1 -> consumer2 -> consumer3 -> producer1 -> producer2 -> producer3 순서로 실행된다.
생산자 우선 결과 분석

- p1 : producer1 생산자 스레드를 뜻한다.
- c1 : consumer1 소비자 스레드를 뜻한다.
- 임계 영역은 synchronized를 영역을 뜻한다. 스레드가 이 영역에 들어가려면 모니터 락( lock )이 필요하다. 설명을 단순화하기 위해 BoundedQueue의 버전 정보는 생략한다.
- 스레드가 처음부터 모두 생성되어 있는 것은 아니지만, 모두 그려두고 시작하겠다.
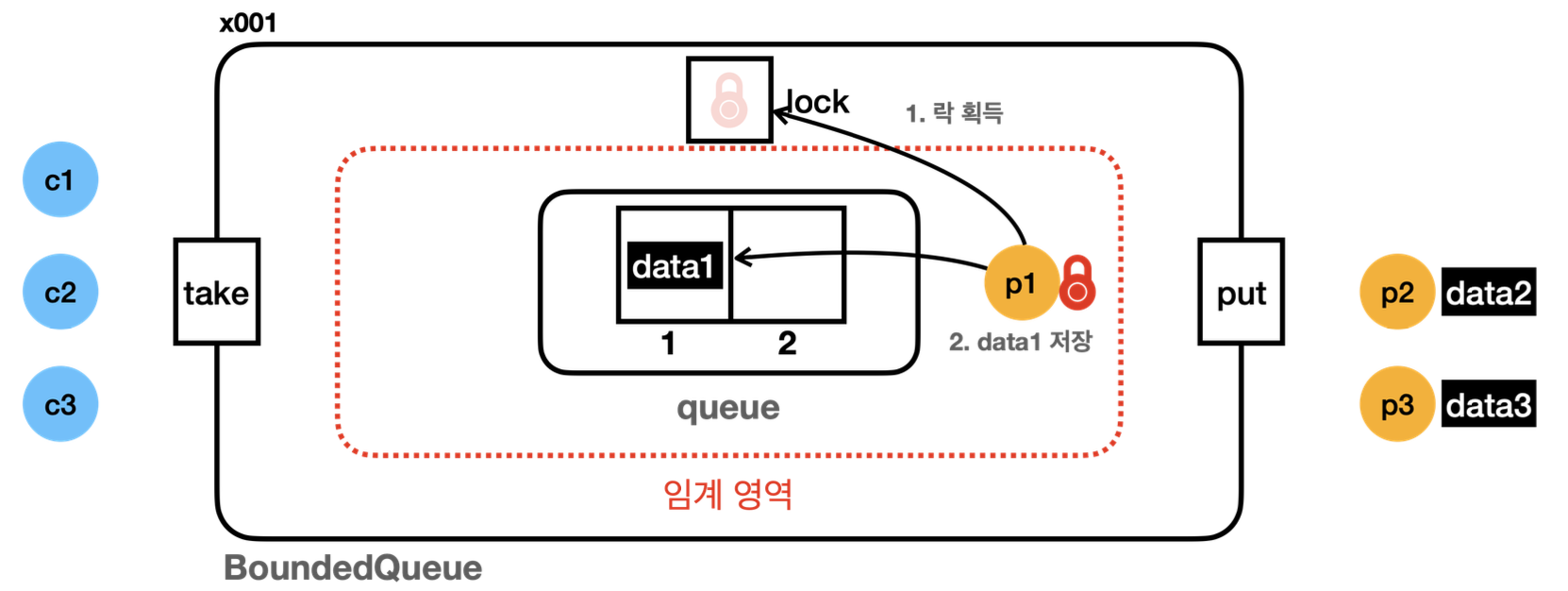
23:06:02.006 [ main] == [생산자 먼저 실행] 시작, BoundedQueueV1 ==
23:06:02.011 [ main] 생산자 시작
23:06:02.036 [producer1] [생산 시도] data1 -> []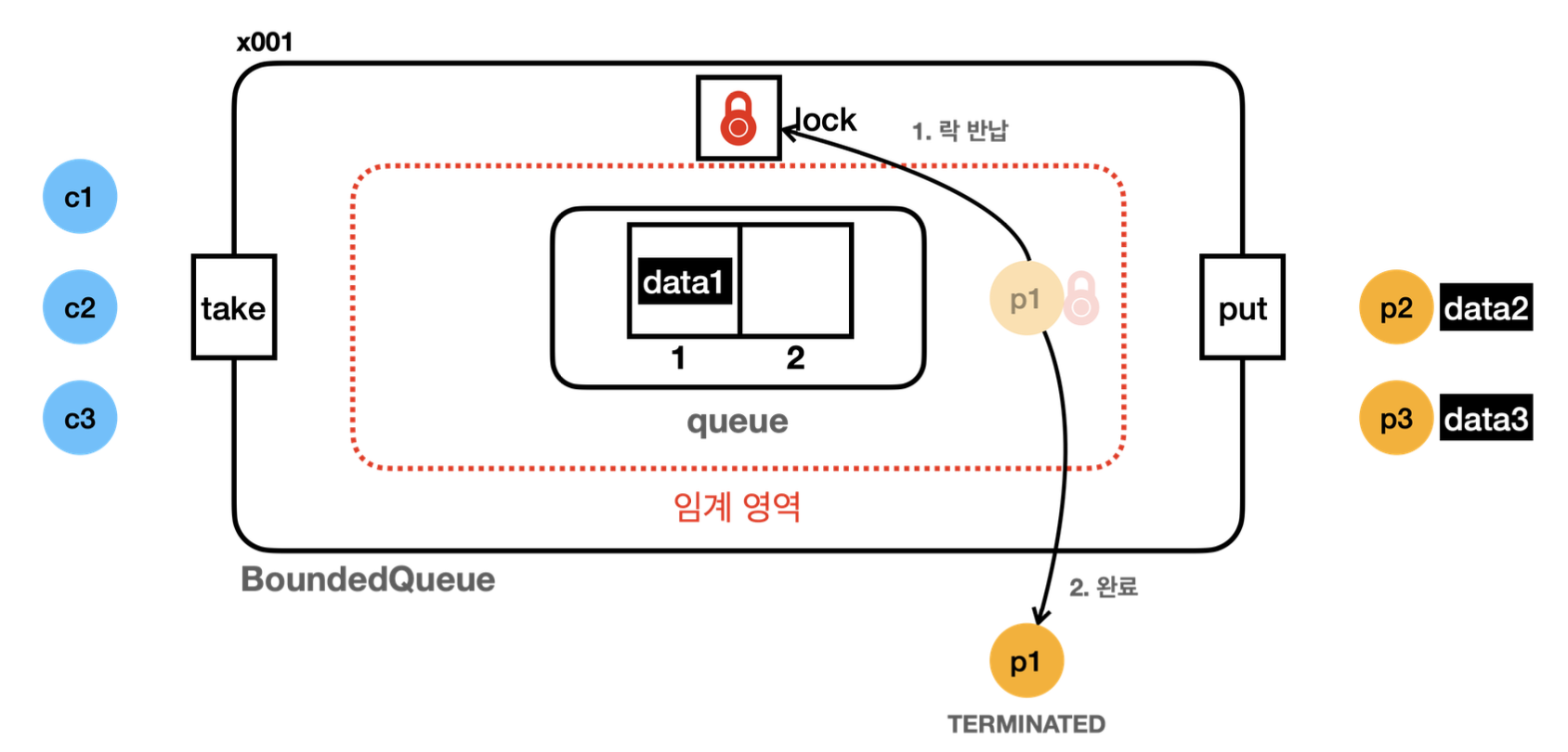
23:07:30.618 [producer1] [생산 완료] data1 -> [data1]
23:07:30.706 [producer2] [생산 시도] data2 -> [data1]
23:07:30.707 [producer2] [생산 완료] data2 -> [data1, data2]
23:07:30.812 [producer3] [생산 시도] data3 -> [data1, data2]
23:07:30.812 [producer3] [put] 큐가 가득 참, 버림: data3- p3는 data3을 큐에 저장하려고 시도한다.
- 하지만 큐가 가득 차 있기 때문에 더는 큐에 데이터를 추가할 수 없다. 따라서 put() 내부에서 data3 은 버린다.
- 데이터를 버리지 않는 대안
- data3을 버리지 않는 대안은, 큐에 빈 공간이 생길 때까지 p3 스레드가 기다리는 것이다. 언젠가는 소비자 스레드가 실행되어서 큐의 데이터를 가져갈 것이고, 큐에 빈 공간이 생기게 된다. 이때 큐에 데이터를 보관하는 것이다.
- 단순하게 생각하면 생산자 스레드가 반복문을 사용해서 큐에 빈 공간이 생기는지 주기적으로 체크한 다음에, 만약 빈 공간이 없다면 sleep()을 짧게 사용해서 잠시 대기하고, 깨어난 다음에 다시 반복문에서 큐의 빈 공간을 체크하는 식으로 구현하면 될 것 같다
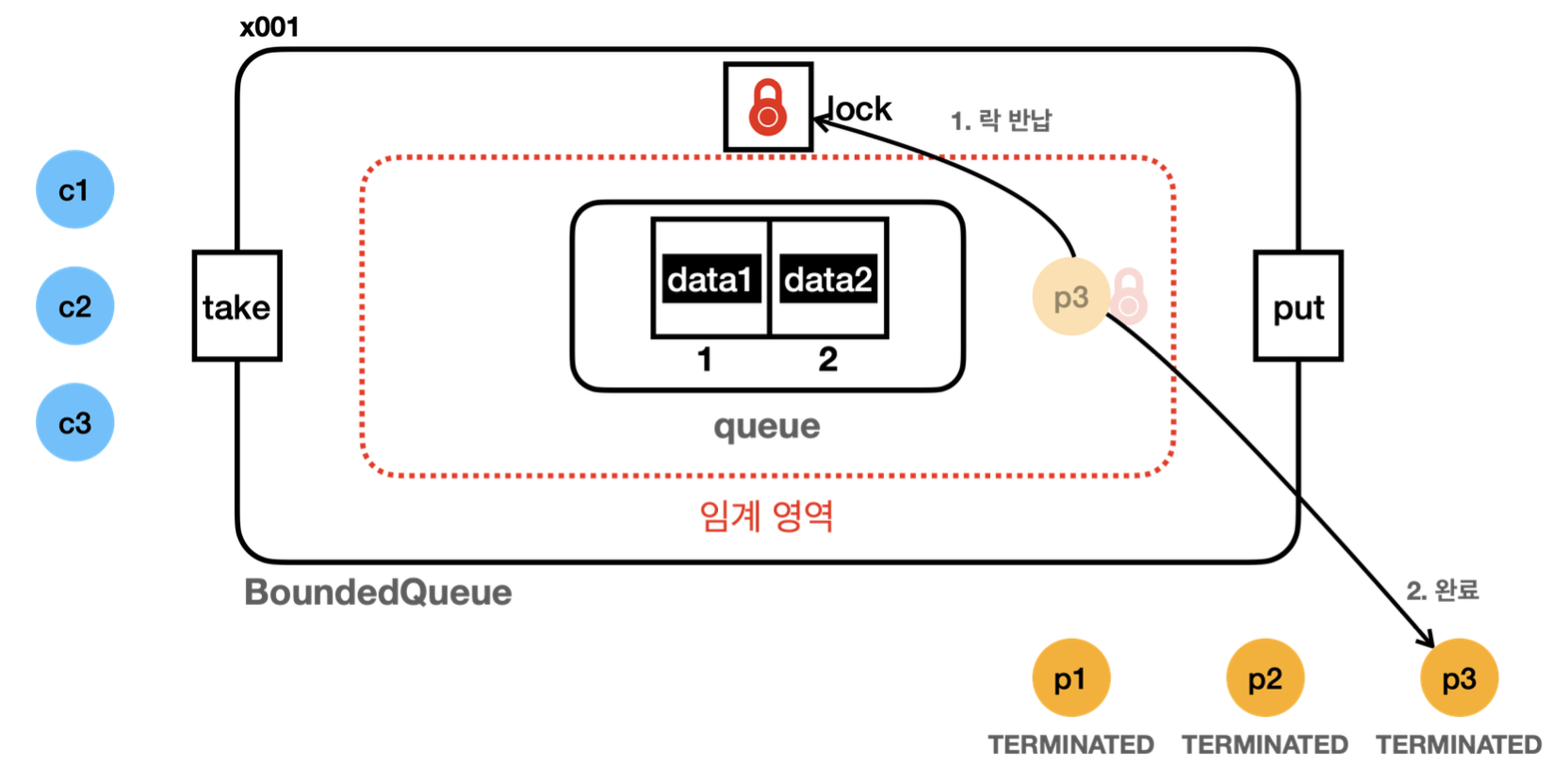
23:13:17.081 [producer3] [생산 완료] data3 -> [data1, data2]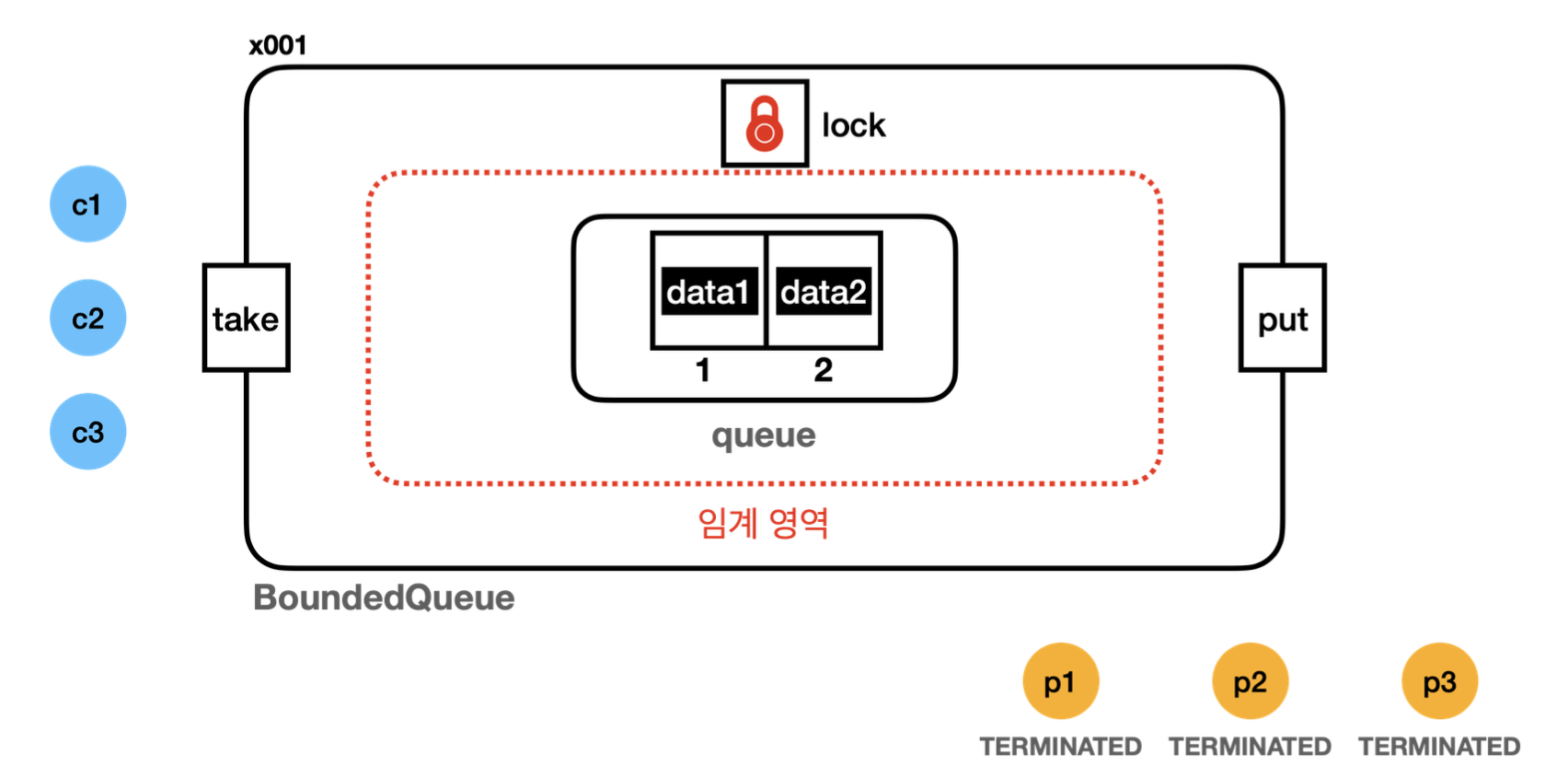
23:13:17.186 [ main] 현재 상태 출력, 큐 데이터: [data1, data2]
23:13:17.186 [ main] producer1: TERMINATED
23:13:17.187 [ main] producer2: TERMINATED
23:13:17.188 [ main] producer3: TERMINATED
23:13:17.189 [ main] 소비자 시작
23:13:17.192 [consumer1] [소비 시도] ? <- [data1, data2]
23:13:17.194 [consumer1] [소비 완료] data1 <- [data2]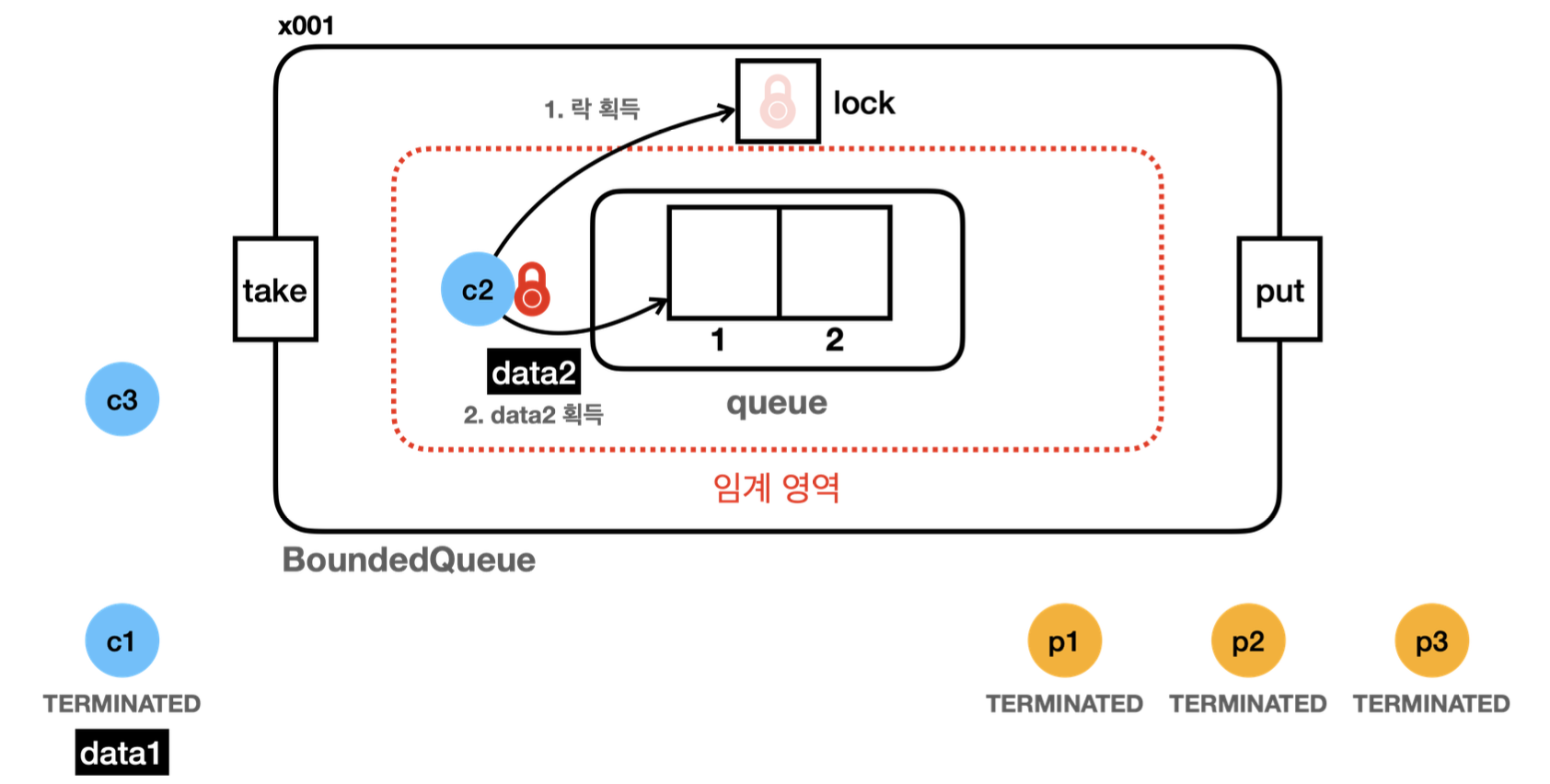
23:13:17.297 [consumer2] [소비 시도] ? <- [data2]
23:13:17.297 [consumer2] [소비 완료] data2 <- []
23:13:17.402 [consumer3] [소비 시도] ? <- []- c3는 큐에서 데이터를 획득하려고 한다.
- 하지만 큐에 데이터가 없기 때문에 데이터를 획득할 수 없다. 따라서 대신에 null을 반환한다.
- 큐에 데이터가 없다면 기다리자.
- 소비자 입장에서 큐에 데이터가 없다면 기다리는 것도 대안이다.
- null을 받지 않는 대안은, 큐에 데이터가 추가될 때까지 c3 스레드가 기다리는 것이다. 언젠가는 생산자 스레드가 실행되어서 큐에 데이터를 추가할 것이다. 물론 생산자 스레드가 계속해서 데이터를 생산한다는 가정이 필요하다.
- 단순하게 생각하면 소비자 스레드가 반복문을 사용해서 큐에 데이터가 있는지 주기적으로 체크한 다음에, 만약 데이터가 없다면 sleep()을 짧게 사용해서 잠시 대기하고, 깨어난 다음에 다시 반복문에서 큐에 데이터가 있는지 체크하는 식으로 구현하면 될 것 같다.
생각해 보면 큐에 데이터가 없는 상황은 앞서 큐의 데이터가 가득 찬 상황과 비슷하다. 한정된 버퍼(Bounded buffer) 문제는 이렇듯 버퍼에 데이터가 가득 찬 상황에 데이터를 생산해서 추가할 때도 문제가 발생하고, 큐에 데이터가 없는데 데이터를 소비할 때도 문제가 발생한다.
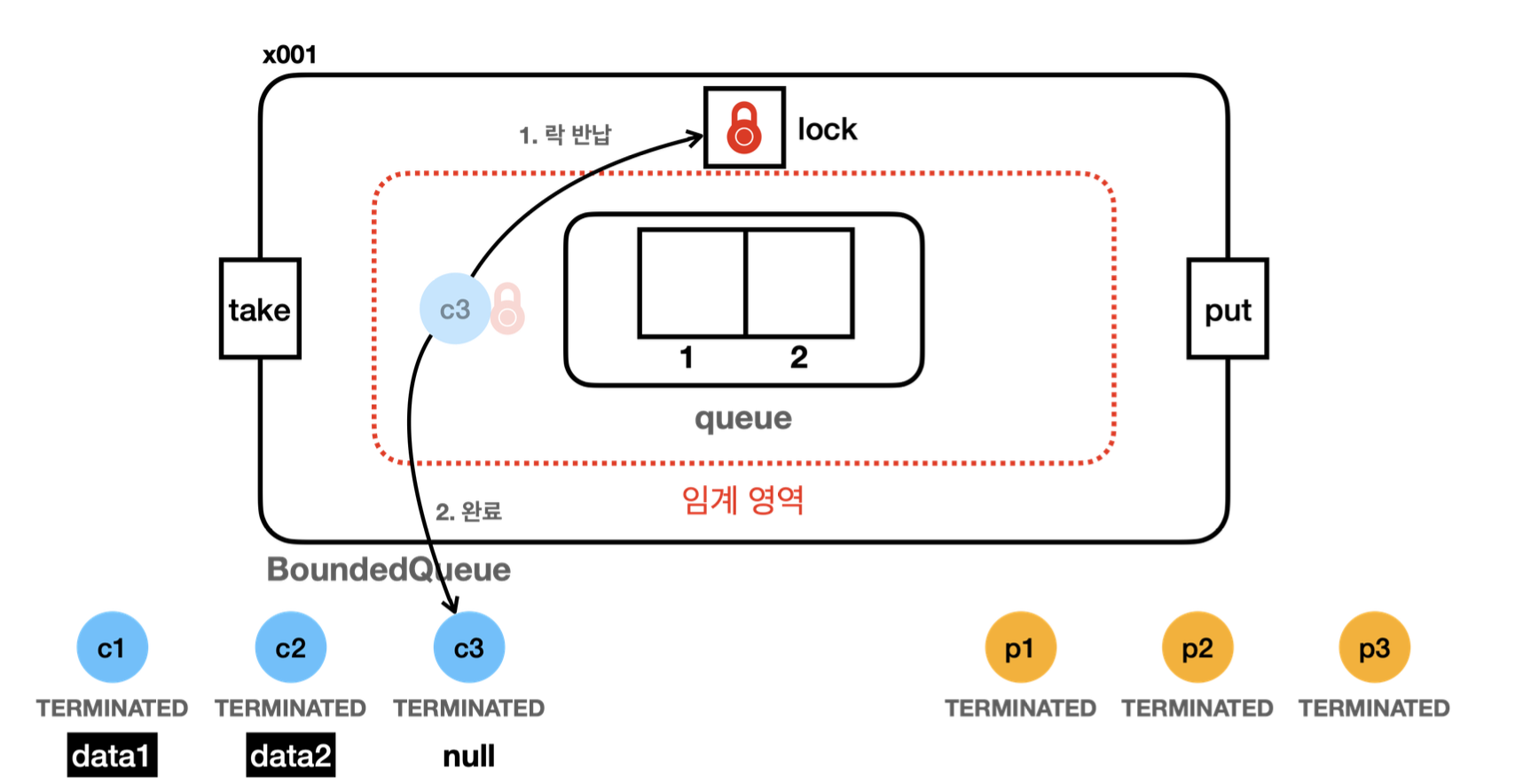
23:13:17.403 [consumer3] [소비 완료] null <- []
23:13:17.504 [ main] 현재 상태 출력, 큐 데이터: []
23:13:17.505 [ main] producer1: TERMINATED
23:13:17.505 [ main] producer2: TERMINATED
23:13:17.505 [ main] producer3: TERMINATED
23:13:17.506 [ main] consumer1: TERMINATED
23:13:17.506 [ main] consumer2: TERMINATED
23:13:17.506 [ main] consumer3: TERMINATED
23:13:17.507 [ main] == [생산자 먼저 실행] 종료, BoundedQueueV1 ==- 결과적으로 버퍼가 가득 차서 p3 가 생산한 data3 은 버려졌다.
- c3 가 데이터를 조회하는 시점에 버퍼는 비어 있어서 데이터를 받지 못하고 null 값을 받았다.
- 스레드가 대기하며 기다릴 수 있다면 p3 가 생산한 data3을 c3 가 받을 수도 있었을 것이다.
소비자 우선 결과 분석
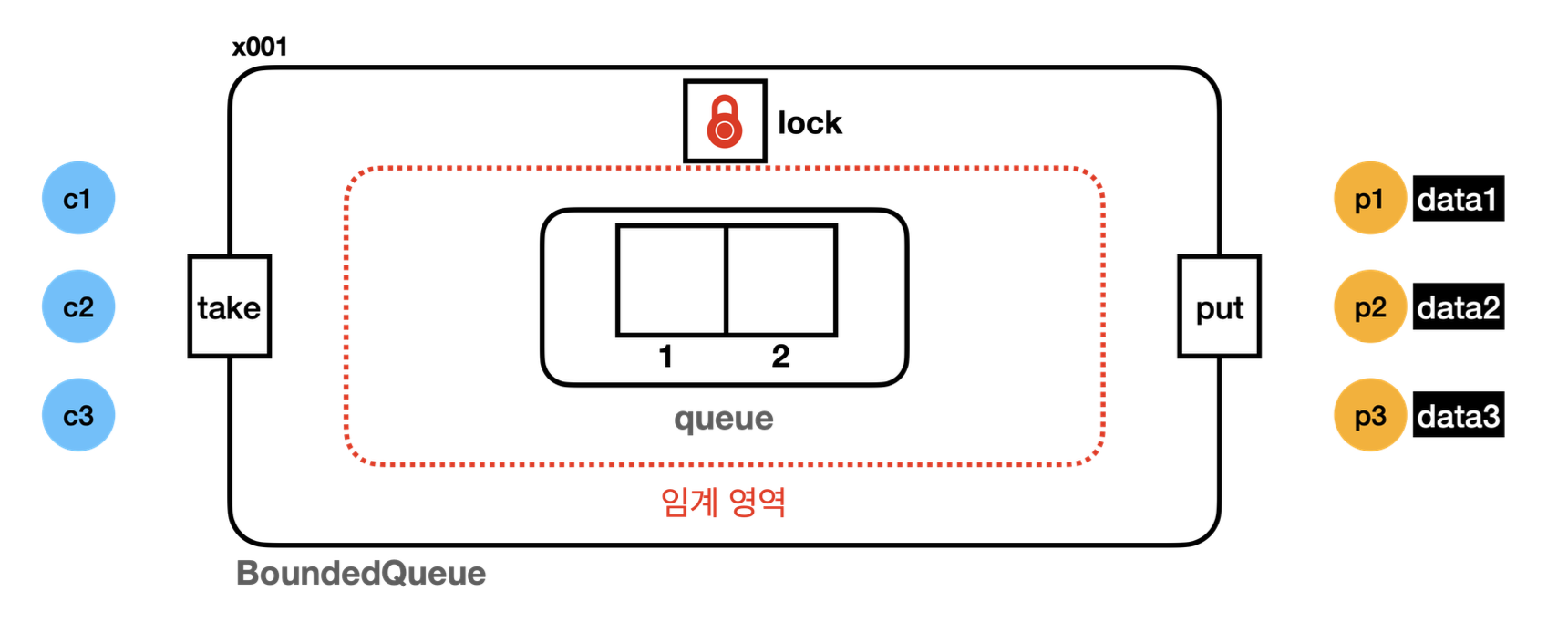
소비자 스레드 실행 시작

23:28:47.774 [ main] == [소비자 먼저 실행] 시작, BoundedQueueV1 ==
23:28:47.781 [ main] 소비자 시작
23:28:47.797 [consumer1] [소비 시도] ? <- []
23:28:47.817 [consumer1] [소비 완료] null <- []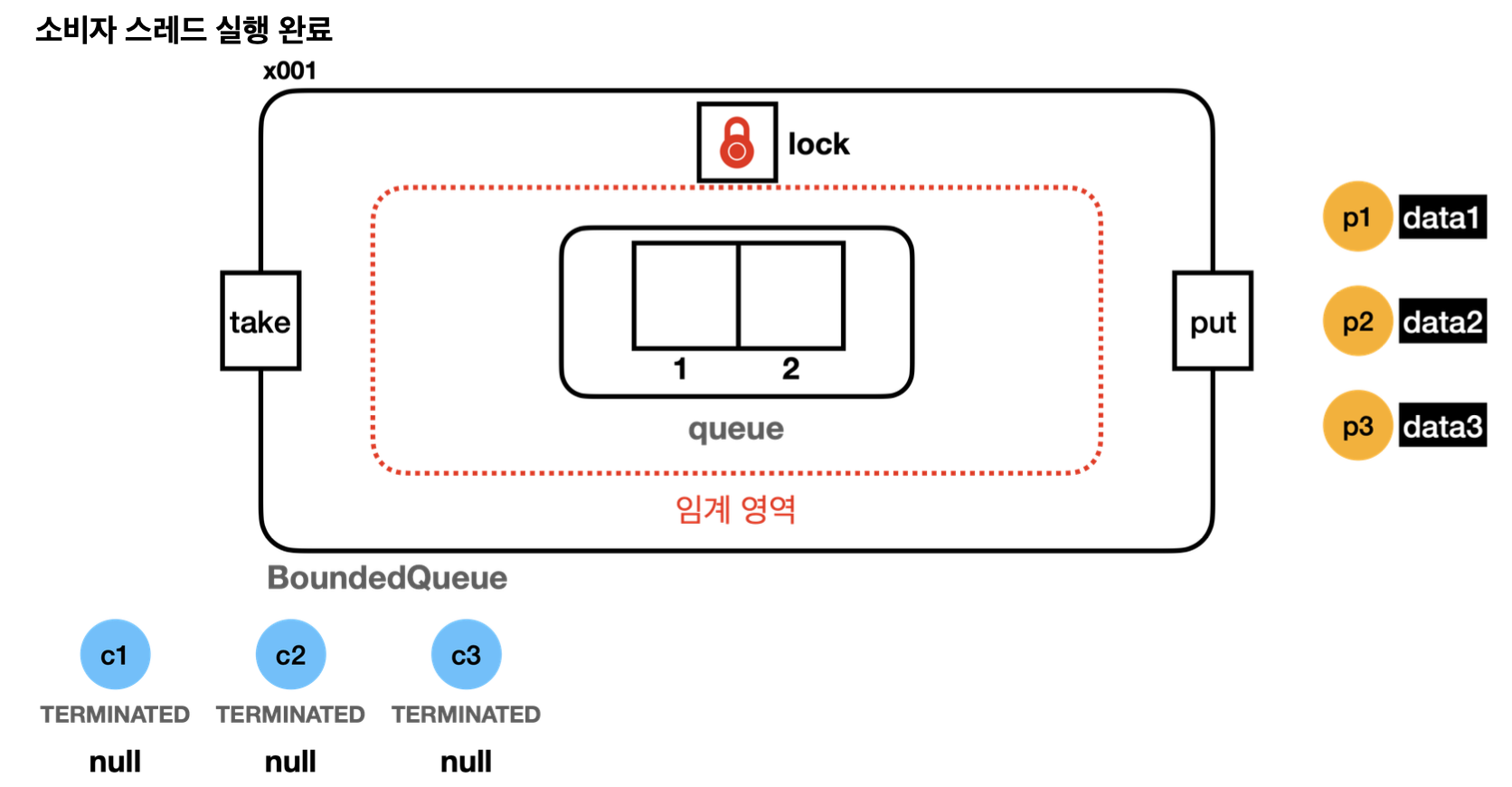
23:28:47.902 [consumer2] [소비 시도] ? <- []
23:28:47.903 [consumer2] [소비 완료] null <- []
23:28:48.008 [consumer3] [소비 시도] ? <- []
23:28:48.008 [consumer3] [소비 완료] null <- []
23:28:48.113 [ main] 현재 상태 출력, 큐 데이터: []
23:28:48.114 [ main] consumer1: TERMINATED
23:28:48.115 [ main] consumer2: TERMINATED- 큐에 데이터가 없으므로 null을 반환한다. 결과적으로 c1 , c2 , c3 모두 데이터를 받지 못하고 종료된다.
- 언젠가 생산자가 데이터를 넣어준다고 가정해 보면 c1 , c2 , c3 스레드는 큐에 데이터가 추가될 때까지 기다리는 것도 방법이다.

23:28:48.116 [ main] 생산자 시작
23:28:48.120 [producer1] [생산 시도] data1 -> []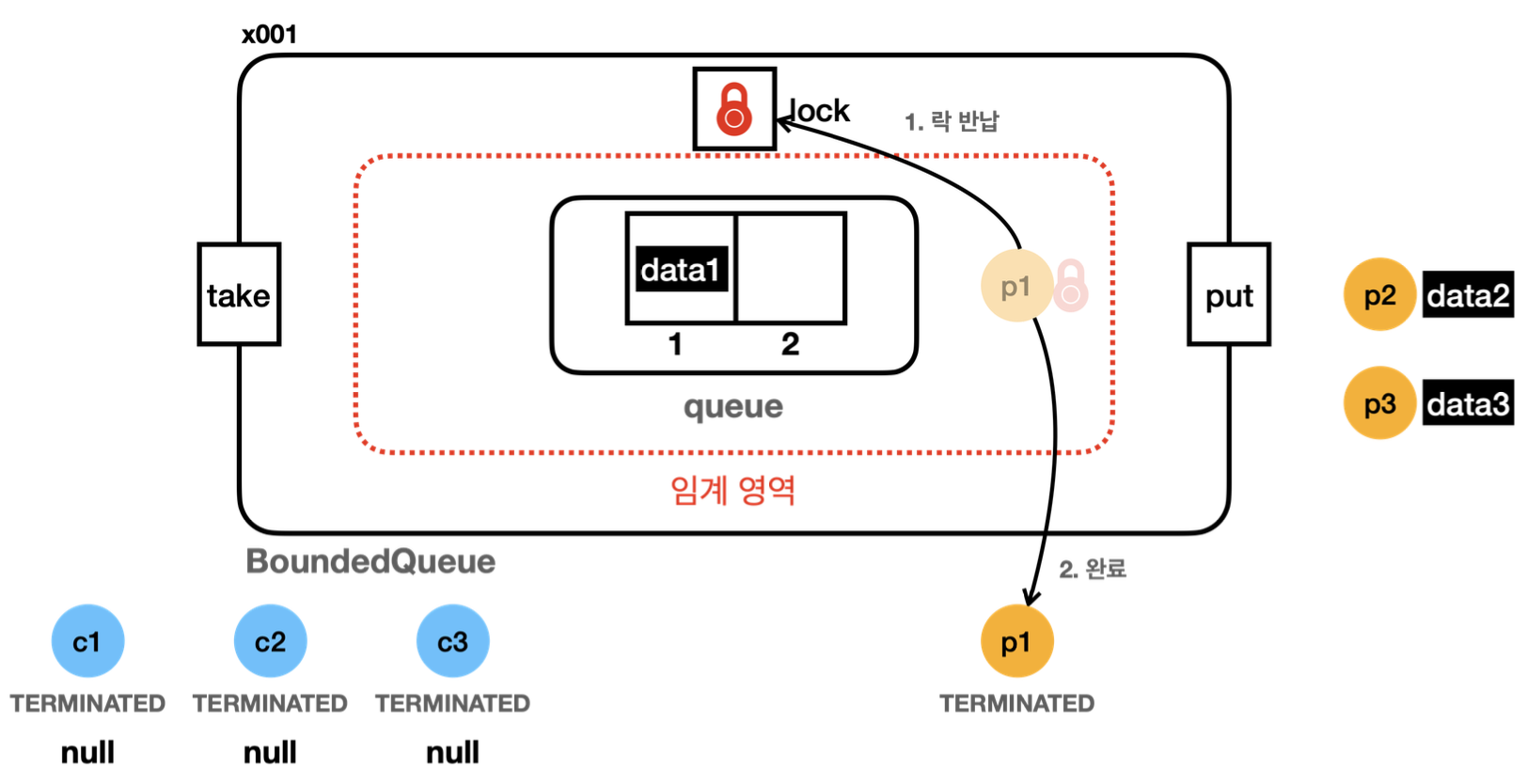
23:28:48.120 [producer1] [생산 시도] data1 -> []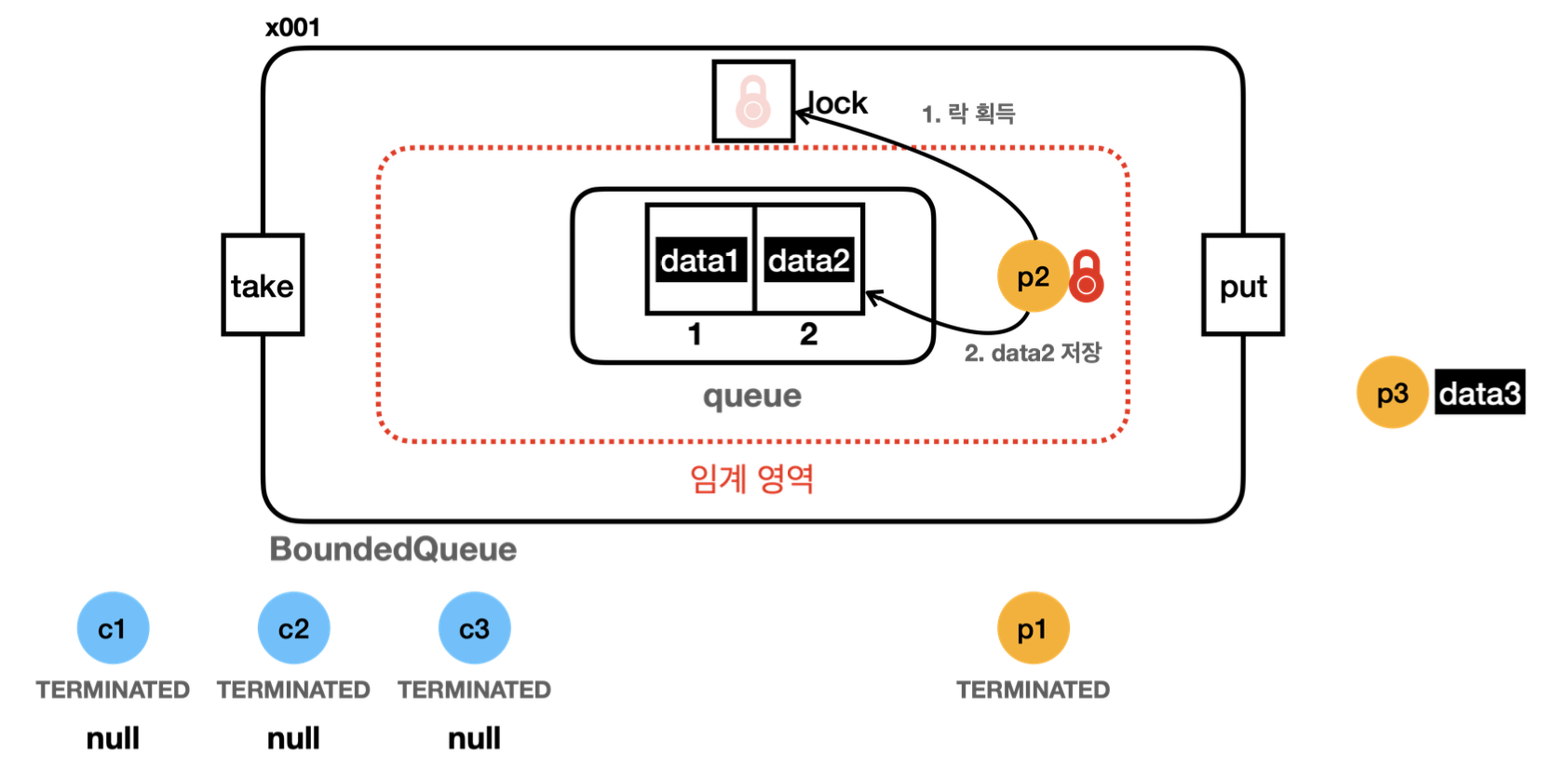
23:28:48.225 [producer2] [생산 시도] data2 -> [data1]
23:28:48.226 [producer2] [생산 완료] data2 -> [data1, data2]
23:28:48.330 [producer3] [생산 시도] data3 -> [data1, data2]
23:28:48.331 [producer3] [put] 큐가 가득 참, 버림: data3- p3의 경우 큐에 데이터가 가득 차서 data3을 포기하고 버린다.
- 소비자가 계속해서 큐의 데이터를 가져간다고 가정하면, p3 스레드는 기다리는 것도 하나의 방법이다

23:28:48.331 [producer3] [생산 완료] data3 -> [data1, data2]
23:28:48.432 [ main] 현재 상태 출력, 큐 데이터: [data1, data2]
23:28:48.432 [ main] consumer1: TERMINATED
23:28:48.433 [ main] consumer2: TERMINATED
23:28:48.433 [ main] consumer3: TERMINATED
23:28:48.434 [ main] producer1: TERMINATED
23:28:48.435 [ main] producer2: TERMINATED
23:28:48.435 [ main] producer3: TERMINATED
23:28:48.435 [ main] == [소비자 먼저 실행] 종료, BoundedQueueV1 ==
문제점
- 생산자 스레드 먼저 실행의 경우 p3 가 보관하는 data3 은 버려지고, c3는 데이터를 받지 못한다. ( null을 받는다.)
- 소비자 스레드 먼저 실행의 경우 c1 , c2 , c3 는 데이터를 받지 못한다.( null을 받는다.) 그리고 p3 가 보관하는 data3 은 버려진다.
예제는 단순하게 설명하기 위해 생산자 스레드 3개, 소비자 스레드 3개를 한 번만 실행했지만, 실제로 이런 생산자/ 소비자 구조는 보통 계속해서 실행된다. 레스토랑에 손님은 계속 찾아오고, 음료 공장은 계속해서 음료를 만들어낸다. 쇼핑몰이라면 고객은 계속해서 주문을 한다.
- 버퍼가 가득 찬 경우: 생산자 입장에서 버퍼에 여유가 생길 때까지 조금만 기다리면 되는데, 기다리지 못하고, 데 이터를 버리는 것은 아쉽다.
- 버퍼가 빈 경우: 소비자 입장에서 버퍼에 데이터가 채워질 때 까지 조금만 기다리면 되는데, 기다리지 못하고, null 데이터를 얻는 것은 아쉽다.
'멀티스레드와 동시성' 카테고리의 다른 글
| Ch08. 생산자 소비자 문제 - 예제3(wait, notify) (0) | 2024.08.23 |
|---|---|
| Ch08. 생산자 소비자 문제 - 예제2(생산자, 소비자 대기) (0) | 2024.08.21 |
| Ch08. 생산자 소비자 문제 - 소개 (0) | 2024.08.20 |
| Ch07. 고급 동기화(concurrent.Lock) - ReentrantLock (0) | 2024.08.15 |
| Ch07. 고급 동기화(concurrent.Lock) - LockSupport (0) | 2024.08.15 |