Apache Kafka Cluster 설치 및 구성
- Confluent Platform(CP) 사용
- Ubuntu 18.04 환경에서 진행
- Production 환경을 가정(Zookeeper 3 대, Broker 3 대, Control Center1) 1 대 구성)
- Kafka Broker 1 개만 사용할 경우(개발 환경), 무료로 모든 기능 사용 가능
- Broker 2개 이상의 클러스터로 구성할 경우, 30일 기한의 라이선스가 자동 생성
- 계속 사용이 필요할 경우 라이선스를 구매해야 함
- Confluent Platform의 시스템 요구사항을 확인할 것
- OpenJDK 혹은 OracleJDK 1.8 / 1.11 사용 가능(본 강의에서는 1.8 버전 사용)
- 머신간 NTP 시간 동기화
Confluent Platform 다운로드
https://www.confluent.io/get-started/
https://www.confluent.io/get-started/
www.confluent.io
Kafka 설치를 위한 OS 관련 구성
Zookeeper 3 대, Broker 3 대, Control Center 1 대 모두 동일
1. Linux 계정 생성
Confluent Platform(Apache Kafka)은 Linux 환경에서 동작 : 관리 편의성을 위해 별도의 계정 생성을 권장

2. JDK 구성
OpenJDK 혹은 Oracle JDK 1.8.0_202(64bit)를 다운로드 받은 후, 로그인한 계정의 Home 디렉터리에 압축파일을 옮기고 해당파일의 압축을 해제
Linux 계정의 환경변수에 Java Home 지정하고 bin 디렉터리를 PATH에 추가
vi ~/.bashrc
export JAVA_HOME=/home/confluent/jdk1.8.0_202
export PATH=${JAVA_HOME}/bin:${PATH}
vi ~/.bash_profile
source ~/.bashrc
source ~/.bashrc #환경변수 적용3. Confluent Platform 압축 파일의 압축 해제
Confluent Platform ZIP 파일을 홈 디렉터리로 복사한 다음, 압축을 해제
계정의 환경 변수에 Confluent Platform Home을 지정하고 bin 디렉터리를 PATH에 추가
cp confluent-6.2.1.zip /home/confluent/
cd /home/confluent
unzip confluent-6.2.1.zip
vi ~/.bashrc
export CONFLUENT_HOME=/home/confluent/confluent-6.2.1 #confluent platform파일이 있는 경로
export PATH=${CONFLUENT_HOME}/bin:${PATH}
source ~/.bashrc # 환경변수 적용Zookeeper Node 구성
${CONFLUENT_HOME}/etc/kafka/zookeeper.properties 파일 내의 중요한 파라미터
- Zookeeper Node들은 구성 파일이 동일해야 함
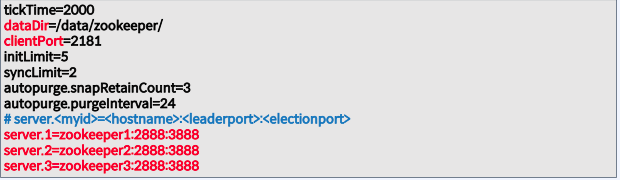
- dataDir 파라미터에 설정한 디렉토리가 생성 되어 있어야 하며, Linux계정(confluent)을 디렉토리에 대한 소유자로 설정
- server.<myid>=<hostname>:<leaderport>:<electionport>
- myid : 서버 식별 번호 → dataDir에 “myid”라는 이름의 파일을 생성하고 myid 값(예, 1 또는 2 또는 3)을 입력 후 저장
- hostname : DNS 또는 /etc/hosts 에 등록된 zookeeper node의 hostname
- leaderport : Follower가 Leader에 연결되는데 사용 (모든 zookeeper node 간에 연결되어야 함)
- electionport: Zookeeper Leader 선출에 사용( 모든 zookeeper node 간에 연결 되어야 함)
${CONFLUENT_HOME}/etc/kafka/server.properties 파일 내의 중요한 파라미터

- zookeeper.connect: Broker에서 Zookeeper를 연결하기 위한 파라미터
- zookeeper1:2181에서 zookeeper1은 DNS 또는 /etc/hosts 에 등록된 zookeeper node의 hostname
- broker.id: 정수로 표현되는 숫자: 같은 Kafkacluster 내의 Broker들은 서로 다른 고유한 broker.id를 가져야 함
- log.dirs 파라미터에 설정한 디렉토리가 생성 되어 있어야 하며, Linux계정(confluent)을 디렉토리에 대한 소유자로 설정
- listeners: Broker가 수신할 URI의 쉼표로 구분된 목록
- broker1은 DNS 또는 /etc/hosts 에 등록된 broker1 node의 hostname
- kafka client가 Broker node와 연결할 때 사용하는 정보
Control Center Node 구성
${CONFLUENT_HOME}/etc/confluent-control-center/control-center-production.properties
파일 내의 중요한 파라미터

- 개발환경: 1대로 구성 가능
- 운영환경: 2대이상 Machine상에 설치, 구성 권장(HA목적)
- ControlCenter는 Zookeeper 및 Broker와 별개의 머신에 설치,구성해야 함
Confluent Platform 실행
1. Zookeeper 실행 (3대의 Zookeeper Node에서 실행)

2. Kafka Broker 실행 (3 대의 Broker Node에서 실행)

3. Control Center 실행 (1대의 Control Center Node에서 실행)

nohup 스크립트 생성 및 실행
nohup Scripts: 별도의 디렉터리를 생성 후 nohup 명령어 script를 만들어서 사용하는 것을 권장
- start_[실행할 component 명].sh
- stop_[실행할 component 명].sh
- log_[실행할 component 명].sh
각 script는 각 컴포넌트를 실행하는 각 머신에서만 작성(예, Broker 머신에는 Broker용 스크립트만 작성)
confluent 계정의 Home 디렉터리에서 bin 폴더 생성 후 bin 폴더로 이동, 작성 후 실행 권한 부여

실행 권한 부여(start스크립트의 예)

Zookeeper용 Start nohup 스크립트
vi start_zookeeper1.sh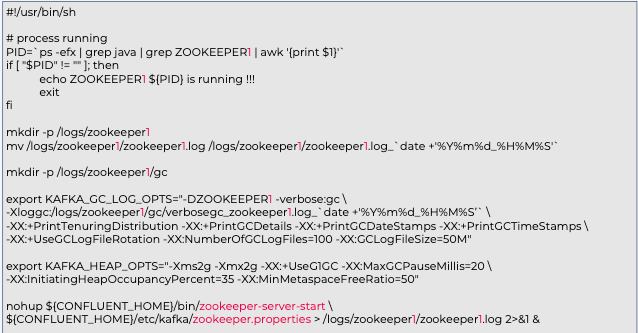
vi stop_zookeeper1.sh
vi start_broker1.sh
vi stop_broker1.sh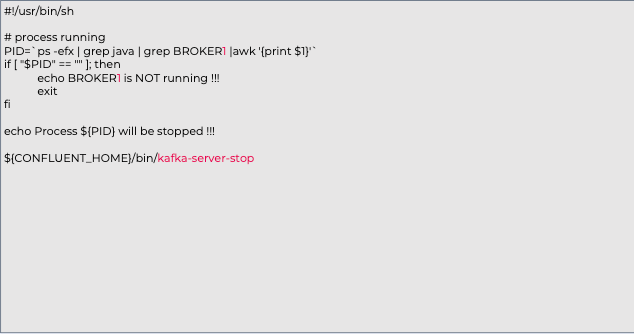
vi start_c3.sh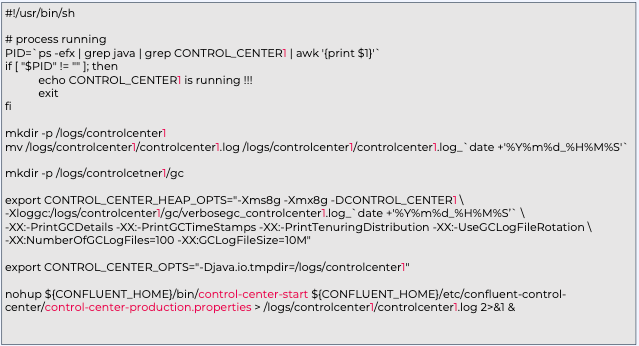
vi stop_c3.sh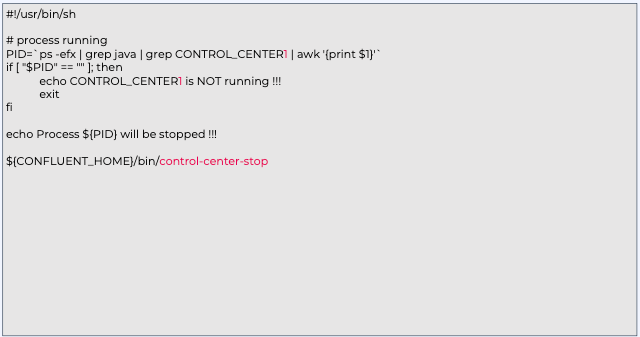
'Kafka 완전 정복 : 클러스터 구축부터 MSA 환경 활용까지 > 기본,심화 개념, 아키텍처와 생태계' 카테고리의 다른 글
| Ch03. Apache Kafka 구성 및 관리 - Kafka Cluster Expansion, Shrink (0) | 2023.05.03 |
|---|---|
| Ch03. Apache Kafka 구성 및 관리 - Log Retention, Cleanup Policy (0) | 2023.05.03 |
| Ch03. Apache Kafka 구성 및 관리 - Kafka in Real Environment (0) | 2023.05.02 |
| Ch03. Apache Kafka 구성 및 관리 - Apache Kafka and Confluent Reference Architecture (0) | 2023.05.02 |
| Ch02. Apache Kafka 심화 개념 및 이해 - Exactly Once Semantics(EOS) (0) | 2023.04.16 |