728x90
Think about Reliability

- Broker에 장애가 발생하면?
- 장애가 발생한 Broker의 Partition들은 모두 사용할 수 없게 되는 문제 발생
Partition 관련 데이터들(Message, Offset)

- Producer가 Write하는 LOG-END-OFFSET과 Consumer Group의 Consumer가 Read하고 처리한 후에 Commit한 CURRENT-OFFSET과의 차이(Consumer Lag)가 발생할 수 있음
다른 Broker에서 Partition을 새로 만들 수 있으면 장애가 해결될까???

- 다른 Broker에서 장애가 발생한 Partition을 대신해서 Partition을 새로 만들면 장애를 해결?
- 새로 들어오는 메시지에 대해서는 문제가 발생하지 않겠지만, 기존에 보낸 메시지는 해결이 되지 않는다.
- 기존에 사용했던 offset 정보도 날라가기 때문에 문제가 발생한다.
- 기존 메시지는 버릴 것인가? 기존 Offset 정보들을 버릴 것인가?
Replication(복제) of Partition
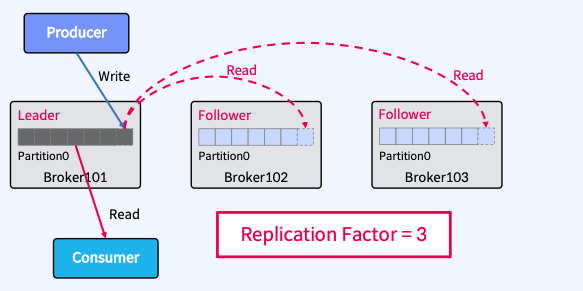
- Partition을 복제(Replication)하여 다른 Broker상에서 복제물(Replicas)을 만들어서 장애를 미리 대비함
- Replicas - Leader Partition(원본 파티션), Follower Partition(복제된 파티션)
- Replication Factor를 사용해서, 복제본에 갯수를 지정할 수 있다.
Producer/Consumer는 Leader와만 통신 Follower는 복제만
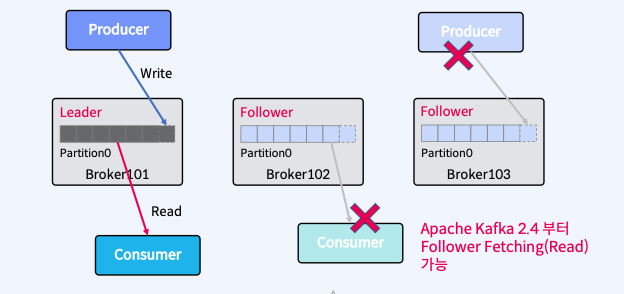
- Producer는 Leader에만 Write하고 Consumer는 Leader로부터만 Read한다.
- Follower는 Broker 장애시 안정성을 제공하기 위해서만 존재한다.
- Follower는 Leader의 Commit Log에서 데이터를 가져오기 요청(Fetch Request)으로 복제한다.
Leader 장애 - 새로운 Leader를 선출

- Leader에 장애가 발생하면?
- Kafka 클러스터는 Follower 중에서 새로운 Leader를 선출한다.
- Clients(Producer/Consumer)는 자동으로 새 Leader로 전환된다.
Partition Leader에 대한 자동 분산 Hot Spot 방지


- 하나의 Broker에만 Partition의 Leader들이 몰려 있다면?
- Follwer에서 데이터를 Read, Write 할 수 없기 때문에 하나의 Broker에만 집중이된다.
- 특정 Broker에만 Client(Producer/Consumer)로 인해 부하 집중
- 아래와 같은 옵션을 통해, 자동 분산 HotSpot 방지 가능하다.
- auto.leader.rebalance.enable : 기본값 -> 자동 분산 Hot Spot 방지 on/off 옵션
- enable leader.imbalance.check.interval.seconds : 기본값 300 sec -> leader가 불균형한지 설정된 초마다 확인해준다.
- leader.imbalance.per.broker.percentage : 기본값 10 -> 다른 브로커보다 몇퍼센트 더 가지고 있을 수 있는지
Rack Awareness(Rack 간 분산하여 Rack 장애를 대비)

- 동일한 Rack 혹은 Available Zone상의 Broker들에 동일한 “rack name” 지정
- 브로커가 다른 위치에 있다는 것을 rack name을 지정해서, 분산시켜 놓는것이다.
- 복제본(Replica-Leader/Follower)은 최대한 Rack 간에 균형을 유지하여 Rack 장애 대비
- Topic 생성시 또는 Auto Data Balancer/Self Balancing Cluster 동작 때만 실행
정리
- Partition을 복제(Replication)하여 다른 Broker상에서 복제물(Replicas)을 만들어서 장애를 미리 대비함
- Replicas-LeaderPartition, FollowerPartition
- Producer는 Leader에만 Write하고 Consumer는 Leader로부터만 Read함
- Follower는 Leader의 CommitLog에서 데이터를 가져오기 요청(FetchRequest)으로 복제
- 복제본(Replica-Leader/Follower)은 최대한 Rack간에 균형을 유지하여 Rack 장애 대비하는 Rack Awareness 기능이 있음
728x90
'Kafka 완전 정복 : 클러스터 구축부터 MSA 환경 활용까지 > 기본,심화 개념, 아키텍처와 생태계' 카테고리의 다른 글
| Ch02. Apache Kafka 심화 개념 및 이해 - Partition Assignment Strategy (0) | 2023.04.16 |
|---|---|
| Ch01. Apache Kafka 기본 개념 및 이해 - In-Sync Replicas (0) | 2023.03.29 |
| Ch01. Apache Kafka 기본 개념 및 이해 - Consume (0) | 2023.03.28 |
| Ch01. Apache Kafka 기본 개념 및 이해 - Producer (0) | 2023.03.28 |
| Ch01. Apache Kafka 기본 개념 및 이해 - Broker, Zookeeper (0) | 2023.03.20 |